Description
|
|
Created by Blen Abate
almost 5 years ago
|
|
Page 1
Semi-conservative replication of DNA when a cell divides, the two strands of the helix separate each original strand serves as a template for the new strands, which are built by adding nucleotides which means each new strand is a combination of one old strand and one new strand this is why DNA is referred to as being semi-conservative the base sequence on the original template is used to make a complementary sequence the base pairs can only be added if it is the complementary base (hydrogen bonds are formed between complementary bases) these bonds don't occur if they're wrong pair complementary base pairing: the rule that one base always pairs with another this ensures that the two DNA molecules are identical to the parent molecule
Page 2
The Enzymes
Helicase a group of enzymes that use energy from ATP the energy is required for breaking hydrogen bonds between complementary bases helicase unwinds the double helix a helicase consists of six globular polypeptides arranged in a donut shape the polypeptides assemble with one strand of the DNA molecule passing through the centre of the donut and the other outside it energy from ATP is used to move the helicase along the DNA, breaking hydrogen bonds helicase causes the unwinding of the helix at the same time as it separates the strands
DNA Polymerase carries out the assembly of the new strands DNA polymerase always moves from the 5' to the 3' direction it adds one nucleotide at a time free nucleotides are available in the area where this occurs once hydrogen bonds have been formed between 2 bases, DNA polymerase forms a covalent bond between the phosphate group of the free nucleotide and the sugar of the nucleotide at the existing end of the new strand the pentose sugar is the 3' terminal, the phosphate group is the 5' terminal DNA polymerase adds on the 5' terminal of the free nucleotide to the 3' terminal of the existing strand
DNA Primase creates one RNA primer on the leading strand creates many RNA primers on the lagging strand (RNA primer is required to start replication)
Ligase connects the gaps between Okazaki fragments
Page 3
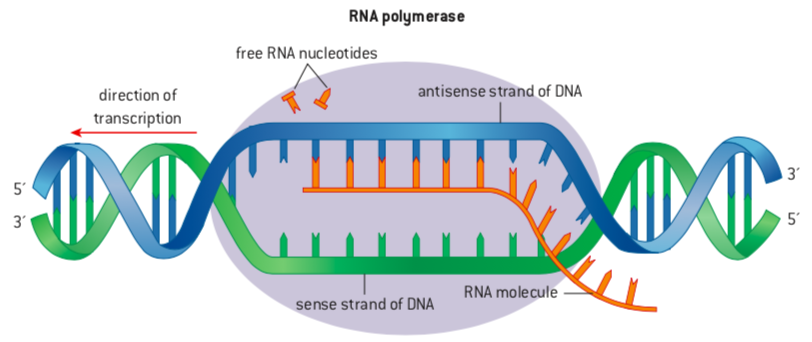
Transcription it is the synthesis of RNA, using DNA as a template RNA is single-stranded so transcription only occurs along one of the two DNA strands starts at the promoter region of the gene, it's just before the gene RNA polymerase binds to DNA and unwinds it one strand of DNA serves as a template for RNA synthesis RNA polymerase moves along the gene, separating RNA into single strands and pairing up RNA nucleotides with complementary bases on one strand of the DNA there's no Thymine in RNA so Uracil pairs with Adenine RNA polymerase forms covalent bonds between the RNA nucleotides the new mRNA is released and the double helix reforms transcription stops at the end of the gene and the completed RNA molecule is released the DNA with the same base sequence as the RNA is called the sense strand the other strand that acts as the template is called the antisense strand it has the complementary base sequence to both the RNA and the sense strand
{kind=link}
Page 4
Translation the mRNA made before leaves the nucleus through pores it enters the cytoplasm and attaches to a ribosome the mRNA is grouped a sequence of 3 bases (codons) amino acids are carried by tRNA along with the anti-codon the tRNA binds to the codon (the amino acid is Met - initiation) the second tRNA binds, a peptide bond forms between the two amino acids the first tRNA leaves, (this starts elongation) the ribosome moves along the mRNA new tRNAs bring an amino acid and more peptide bonds form it reaches a stop codon (this is termination)
{kind=link}
Page 5
Messenger RNA and the genetic code the average length of mRNA for mammals is about 2,000 nucleotides only certain genes are transcribed and only certain types of mRNA will be available for translation in the cytoplasm cells that need or secrete large amounts of a particular polypeptide make any copies of the mRNA for that polypeptide for example, insulin-secreting cells in the pancreas make many copies of the mRNA needed to make insulin there's also tRNA and rRNA
Codons a sequence of three bases on the mRNA each codon codes for a specific amino acid to be added to the polypeptide different codons can code for the same amino acid for this reason, the code is said to be "degenerate" there are also "stop" codons that code for the end of translation amino acids are carried on tRNA, it has a three-base anticodon complementary to the mRNA codon for that particular amino acid
Codons and anticodons three components work together to synthesize polypeptides by translation: mRNA has a sequence of codons that specifies the amino acid sequence of the polypeptide tRNA molecules have an anticodon of three bases that binds to a complementary codon on mRNA and they carry the amino acid corresponding to that codon ribosomes act as the binding site for mRNA and tRNAs and also catalyze the assembly of the polypeptide the accuracy of translation depends on the complementary base pairing between the anticodon on each tRNA and the codon on the mRNA mistakes are very rare, so polypeptides with a sequence of hundreds of amino acids are regularly made with every amino acid correct
Page 6
Mutations
Point mutations are changes to one base in the DNA code and may involve either: The substitution of a base (e.g. ATG becomes ACG) The insertion of a base (e.g. ATG becomes ATCG) The deletion of a base (e.g. ATG becomes AG) The inversion of bases (e.g. ATG becomes AGT) Base substitutions may create either silent, missense or nonsense mutations, while insertions and deletions cause frameshift mutations
Silent mutations occur when the DNA change does not alter the amino acid sequence of the polypeptide This is possible because the genetic code is degenerate and certain codons may code for the same amino acid Missense mutations occur when the DNA change alters a single amino acid in the polypeptide chain Sickle cell anemia is an example of a disease caused by a single base substitution mutation (GAG → GTG ; Glu → Val) Nonsense mutations occur when the DNA change creates a premature STOP codon which truncates the polypeptide Cystic fibrosis is an example of a disease which can result from a nonsense mutation (this may not be the only cause though) Frameshift mutations occur when the addition or removal of a base alters the reading frame of the gene This change will affect every codon beyond the point of mutation and thus may dramatically change the amino acid sequence
Want to create your own Notes for free with GoConqr? Learn more.