Description
|
|
Created by Gaurav Sehgal
about 6 years ago
|
|
Page 1
Identity and Access Management
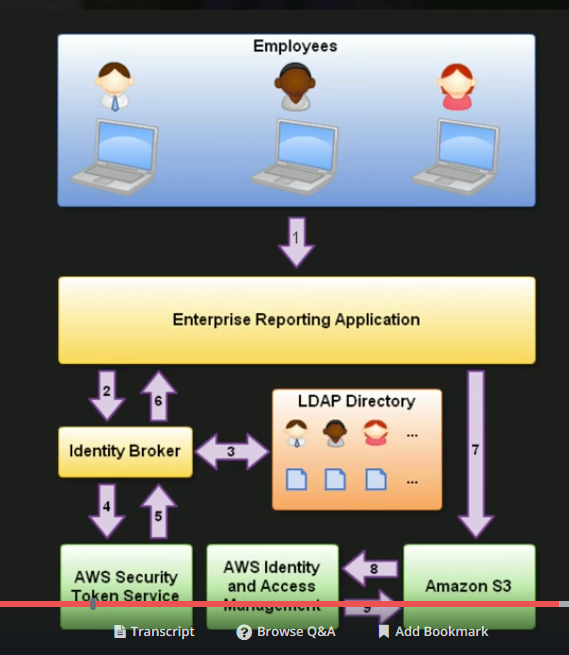
Features of IAM Centralized control of your AWS account Shared access to your AWS account Granular Permissions Identity federation using active directory, facebook, linkedin etc. Multi factor authentication Provides temporary access to users, devices or services wherever and whenever necessary Allows setting up of password rotation policy Integrates with many different AWS services Supports PCI-DSS compliance IAM is a global service and is not fixed to any region. Components of IAM Users (can be an individual, user or application requiring access to AWS services) - A user can belong to multiple groups Groups (users with similar permissions) Roles (these can be created and assigned to AWS resources. i.e. you might have an EC2 instance, and give it a role saying it can access S3. That way the EC2 instance can directly access S3 without having to manage usernames, passwords, etc. ) Policies (documents that define one or more permissions. Policies are applied to Users, Groups and Roles) IAM is NOT an identity store or an authorization system for your applications. If you are migrating an application from on premise to AWS cloud, then the authentication/authorization mechanism for the application would continue to work on AWS. If your application identities (authentication and authorization mechanisms) are based on Active directory, your active directory service can be extended to the AWS cloud. A great solution is the use the AWS Directory service, which is an Active Directory compatible directory service that can work on its own or integrate with your on premise AD service. Amazon Cognito is used for identity management of mobile applications IAM can be accessed (you can manage users, groups and permissions) via - AWS Management Console CLI (Programmatic access) AWS SDKs (through REST APIs via one of the SDKs - this is also a type of programmatic access) Amazon Partner network (APN) provides a rich ecosystem of tools to manage and extend the IAM Policies are written in Java Script Object Notation (JSON) The “ PowerUserAccess” policy provides full access to AWS services and resources, but does not allow management of users and groups. There are two ways to access AWS: Username + Password Access Key ID + Secret Access Key Any new users (except the root user) do not have any permissions by default There are two types of keys that are assigned to each new users, when created in IAM. The keys should be saved at a secure location as you can only view them once (when they are created). If you lose them, you need to re-generate them. Access key Secret access key It is recommended that you set up multi factor authentication on your root account. Username and Password - Cannot be used to interact with the API Can be used to sign in via a custom sign-in link which you can create via the IAM console i.e. Principals: IAM identities that are allowed to interact with an AWS resource. There are three types of Principals - Root user - has access to all AWS cloud services and resources in the account, can also close the account IAM user - persistent identities created for individual people or applications, do not have an expiry - until deleted by the root user Roles/Temporary Security tokens - used to grant privileges to specific actors for a set duration of time. Actors are authenticated by AWS or an external system, following which AWS provides the actor a temporary token from the AWS Security Token Service (STS) to access a service or resource. Lifetime of the temporary security token can be from 15 minutes to 36 hours. Some use cases for roles and temporary security tokens/Types of roles AWS Service (eg. Amazon EC2 roles) Cross account access (grant permissions to users from other AWS accounts, whether you control these accounts or not). This is a highly recommended method as opposed to distributing access keys outside your organization Federation using Web Identity (grant permissions to users authenticated by a trusted external system such as Amazon, facebook, linkedin, google - also knows as IAM identity providers). This is done via OpenID Connect (OIDC) - used a lot for mobile apps Federation using Active Directory - uses Security Insertion Markup language (SAML) IAM authenticates a principal in three ways - Username/Password - for console login Access key - Combination of access key and access secret key, used for programmatic access using CLI and SDK Access key/session token - Used in roles. Temporary security token provides the access key. Combination of access key and session token are used to authenticate Policy documents contain permissions and permissions define the following - Effect - Allow or deny (Single word) Service - what AWS service the policy applies to Resource - which Amazon resource it applies to (S3, EC2, IAM user etc.). Each resource has an ARN (Amazon Resource name). "*" means any resource. Action - Actions within the service/API calls that the permission allows or denies (e.g grant read access to an S3 bucket) to the service Condition - Optionally defines one or more conditions (e.g resource calls should come from a specific IP) Managed policies like Amazon EC2ReadOnlyAccess are pre built policies (created by AWS or your administrator) that can be attached to an IAM user or group. Any changes to these policies are immediately applied to all user and groups attached with the policy. Two types - AWS Managed and Customer managed. Inline policies are different from managed policies in the sense that they are assigned to just one user or group. These policies are used to grant permissions for one off situations. What problems does IAM solve? IAM makes it easy to provide multiple users secure access to your AWS resources. IAM enables you to: Manage IAM users and their access: You can create users in AWS's identity management system, assign users individual security credentials (such as access keys, passwords, multi-factor authentication devices), or request temporary security credentials to provide users access to AWS services and resources. You can specify permissions to control which operations a user can perform. Manage access for federated users: You can request security credentials with configurable expirations for users who you manage in your corporate directory, allowing you to provide your employees and applications secure access to resources in your AWS account without creating an IAM user account for them. You specify the permissions for these security credentials to control which operations a user can perform. If the AWS account has access to resources from a different AWS account, its users may be able to access data under those AWS accounts. Any AWS resources created by a user are under control of and paid for by its AWS account. A user cannot independently subscribe to AWS services or control resources. What kinds of security credentials can IAM users have? IAM users can have any combination of credentials that AWS supports, such as an AWS access key, X.509 certificate, SSH key, password for web app logins, or an MFA device. This allows users to interact with AWS in any manner that makes sense for them. An employee might have both an AWS access key and a password; a software system might have only an AWS access key to make programmatic calls; IAM users might have a private SSH key to access AWS CodeCommit repositories; and an outside contractor might have only an X.509 certificate to use the EC2 command-line interface. Q: Who is able to manage users for an AWS account? The AWS account holder can manage users, groups, security credentials, and permissions. In addition, you may grant permissions to individual users to place calls to IAM APIs in order to manage other users. For example, an administrator user may be created to manage users for a corporation—a recommended practice. When you grant a user permission to manage other users, they can do this via the IAM APIs, AWS CLI, or IAM console. Q: Can I structure a collection of users in a hierarchical way, such as in LDAP? Yes. You can organize users and groups under paths, similar to object paths in Amazon S3—for example /mycompany/division/project/joe Q: Can I define users regionally? Not initially. Users are global entities, like an AWS account is today. No region is required to be specified when you define user permissions. Users can use AWS services in any geographic region. Q: What kind of key rotation is supported for IAM users? User access keys and X.509 certificates can be rotated just as they are for an AWS account's root access identifiers. You can manage and rotate programmatically a user's access keys and X.509 certificates via the IAM APIs, AWS CLI, or IAM console. Q: Can IAM users have individual EC2 SSH keys? Not in the initial release. IAM does not affect EC2 SSH keys or Windows RDP certificates. This means that although each user has separate credentials for accessing web service APIs, they must share SSH keys that are common across the AWS account under which users have been defined. Q: Do IAM user names have to be email addresses? No, but they can be. Q: Which character sets can I use for IAM user names? You can only use ASCII characters for IAM entities. Q: Can I define a password policy for my user’s passwords? Yes, you can enforce strong passwords by requiring minimum length or at least one number. You can also enforce automatic password expiration, prevent re-use of old passwords, and require a password reset upon the next AWS sign-in. Q: Can I set usage quotas on IAM users? No. All limits are on the AWS account as a whole. For example, if your AWS account has a limit of 20 Amazon EC2 instances, IAM users with EC2 permissions can start instances up to the limit. You cannot limit what an individual user can do. Q: What is an IAM role? An IAM role is an IAM entity that defines a set of permissions for making AWS service requests. IAM roles are not associated with a specific user or group. Instead, trusted entities assume roles, such as IAM users, applications, or AWS services such as EC2. Q: What problems do IAM roles solve? IAM roles allow you to delegate access with defined permissions to trusted entities without having to share long-term access keys. You can use IAM roles to delegate access to IAM users managed within your account, to IAM users under a different AWS account, or to an AWS service such as EC2. Q: How do I assume an IAM role? You assume an IAM role by calling the AWS Security Token Service (STS) AssumeRole APIs (in other words, AssumeRole, AssumeRoleWithWebIdentity, and AssumeRoleWithSAML). These APIs return a set of temporary security credentials that applications can then use to sign requests to AWS service APIs. Q: How many IAM roles can I assume? There is no limit to the number of IAM roles you can assume, but you can only act as one IAM role when making requests to AWS services. Q: What is the difference between an IAM role and an IAM user? An IAM user has permanent long-term credentials and is used to directly interact with AWS services. An IAM role does not have any credentials and cannot make direct requests to AWS services. IAM roles are meant to be assumed by authorized entities, such as IAM users, applications, or an AWS service such as EC2. Use IAM roles to delegate access within or between AWS accounts. Q: How many policies can I attach to an IAM role? For inline policies: You can add as many inline policies as you want to a user, role, or group, but the total aggregate policy size (the sum size of all inline policies) per entity cannot exceed the following limits: User policy size cannot exceed 2,048 characters. Role policy size cannot exceed 10,240 characters. Group policy size cannot exceed 5,120 characters. For managed policies: You can add up to 10 managed policies to a user, role, or group. The size of each managed policy cannot exceed 6,144 characters. Q: How many IAM roles can I create? You are limited to 1,000 IAM roles under your AWS account. If you need more roles, submit the IAM limit increase request form with your use case, and we will consider your request. Q: Can I use the same IAM role on multiple EC2 instances? Yes. Q: Can I change the IAM role on a running EC2 instance? Yes. Although a role is usually assigned to an EC2 instance when you launch it, a role can also be assigned to an EC2 instance that is already running. Q: Can I associate an IAM role with an Auto Scaling group? Yes. You can add an IAM role as an additional parameter in an Auto Scaling launch configuration and create an Auto Scaling group with that launch configuration. All EC2 instances launched in an Auto Scaling group that is associated with an IAM role are launched with the role as an input parameter Q: Can I associate more than one IAM role with an EC2 instance? No. You can only associate one IAM role with an EC2 instance at this time. This limit of one role per instance cannot be increased. Q: What happens if I delete an IAM role that is associated with a running EC2 instance? Any application running on the instance that is using the role will be denied access immediately. Which permissions are required to launch EC2 instances with an IAM role? You must grant an IAM user two distinct permissions to successfully launch EC2 instances with roles: Permission to launch EC2 instances. Permission to associate an IAM role with EC2 instances. Q: Can I use a managed policy as a resource-based policy? Managed policies can only be attached to IAM users, groups, or roles. You cannot use them as resource-based policies. Q: How do I set granular permissions using policies? Using policies, you can specify several layers of permission granularity. First, you can define specific AWS service actions you wish to allow or explicitly deny access to. Second, depending on the action, you can define specific AWS resources the actions can be performed on. Third, you can define conditions to specify when the policy is in effect (for example, if MFA is enabled or not). Q: How do I rotate the temporary security credentials on the EC2 instance? The AWS temporary security credentials associated with an IAM role are automatically rotated multiple times a day. New temporary security credentials are made available no later than five minutes before the existing temporary security credentials expire. Q: What is a service-linked role? A service-linked role is a type of role that links to an AWS service (also known as a linked service) such that only the linked service can assume the role. Using these roles, you can delegate permissions to AWS services to create and manage AWS resources on your behalf. Q: Are IAM actions logged for auditing purposes? Yes. You can log IAM actions, STS actions, and AWS Management Console sign-ins by activating AWS CloudTrail. Q: Does AWS Billing provide aggregated usage and cost breakdowns by user? No, this is not currently supported. Q: Can a user access the AWS accounts billing information? Yes, but only if you let them. In order for IAM users to access billing information, you must first grant access to the Account Activity or Usage Reports. What is an AWS account alias? The account alias is a name you define to make it more convenient to identify your account. You can create an alias using the IAM APIs, AWS Command Line Tools, or the IAM console. You can have one alias per AWS account. Q: Can I use a managed policy as a resource-based policy? Managed policies can only be attached to IAM users, groups, or roles. You cannot use them as resource-based policies. Q: How do I set granular permissions using policies? Using policies, you can specify several layers of permission granularity. First, you can define specific AWS service actions you wish to allow or explicitly deny access to. Second, depending on the action, you can define specific AWS resources the actions can be performed on. Third, you can define conditions to specify when the policy is in effect (for example, if MFA is enabled or not). Q: Can I grant permissions to access or change account-level information (for example, payment instrument, contact email address, and billing history)? Yes, you can delegate the ability for an IAM user or a federated user to view AWS billing data and modify AWS account information. Types of credentials AWS uses for authentication of users that can access AWS resources - Passwords - For root or IAM user access to AWS console. Can be between 6 and 128 characters (also needed to log in to discussion forums and support center) Multifactor authentication (MFA) - Requires in addition to password - 6 digit code. Virtual MFAs are more convenient than hardware MFAs because more MFA applications can host more than one virtual MFA device, but could be less secure as the MFA application will run on a less secure device such as a smartphone, rather than a hardware device. Access keys - includes an access key ID (AKI) and a secret access key (SAK) ID for programmatic access. AWS requires that all API requests much include digital signatures that AWS can use to verify the identity of the requester. Access keys help enable that Key Pairs - Amazon EC2 supports SSH keys for gaining first access to the instances. In Amazon Cloudfront, you use key pairs to create signed URLs for private content that you want to distribute to people who have paid for it. Amazon Cloudfront key pairs can only be created by a root user and NOT by an IAM user X.509 certificates - Used for sign SOAP based requests. In addition to SOAP requests, X.509 certificates are used as SSL/TLS server certificates for customers who want to use https to encrypt their transmissions. Q. Can I use virtual, hardware, or SMS MFA with multiple AWS accounts? No. The MFA device or mobile phone number associated to virtual, hardware, and SMS MFA is bound to an individual AWS identity (IAM user or root account). Q. How does AWS MFA work? There are two primary ways to authenticate using an AWS MFA device: AWS Management Console users: When a user with MFA enabled signs in to an AWS website, they are prompted for their user name and password (the first factor–what they know), and an authentication response from their AWS MFA device (the second factor–what they have). All AWS websites that require sign-in, such as the AWS Management Console, fully support AWS MFA. You can also use AWS MFA together with Amazon S3 secure delete for additional protection of your S3 stored versions. AWS API users: You can enforce MFA authentication by adding MFA restrictions to your IAM policies. To access APIs and resources protected in this way, developers can request temporary security credentials and pass optional MFA parameters in their AWS Security Token Service (STS) API requests (the service that issues temporary security credentials). MFA-validated temporary security credentials can be used to call MFA-protected APIs and resources. Note: AWS STS and MFA-protected APIs do not currently support U2F security key as MFA. How do I provision a new virtual MFA device? You can configure a new virtual MFA device in the IAM console for your IAM users as well as for your AWS root account. You can also use the aws iam create-virtual-mfa-device command in the AWS CLI or the CreateVirtualMFADevice API to provision new virtual MFA devices under your account. The aws iam create-virtual-mfa-device and the CreateVirtualMFADevice API return the required configuration information, called a seed, to configure the virtual MFA device in your AWS MFA compatible application Q. If I enable AWS MFA for my AWS root account or IAM users, do they always need to complete the MFA challenge to directly call AWS APIs? No, it’s optional. However, you must complete the MFA challenge if you plan to call APIs that are secured by MFA-protected API access. If you are calling AWS APIs using access keys for your AWS root account or IAM user, you do not need to enter an MFA code. For security reasons, we recommend that you remove all access keys from your AWS root account and instead call AWS APIs with the access keys for an IAM user that has the required permission Does AWS MFA affect how I access AWS Service APIs? AWS MFA changes the way IAM users access AWS Service APIs only if the account administrator(s) choose to enable MFA-protected API access. Administrators may enable this feature to add an extra layer of security over access to sensitive APIs by requiring that callers authenticate with an AWS MFA device. For more information, see the MFA-protected API access documentation in more detail. Other exceptions include S3 PUT bucket versioning, GET bucket versioning, and DELETE object APIs, which allow you to require MFA authentication to delete or change the versioning state of your bucket. I was recently asked to resync my MFA device because my MFA codes were being rejected. Should I be concerned? No, this can happen occasionally. Virtual and hardware MFA relies on the clock in your MFA device being in sync with the clock on our servers. Sometimes, these clocks can drift apart. If this happens, when you use the MFA device to sign in to access secure pages on the AWS website or the AWS Management Console, AWS automatically attempts to resync the MFA device by requesting that you provide two consecutive MFA codes (just as you did during activation). My MFA device is lost, damaged, stolen, or not working, and now I can’t sign in to the AWS Management Console. What should I do? If your MFA device is associated with an AWS root account: You can reset your MFA device on the AWS Management Console by first signing in with your password and then verifying the email address and phone number associated with your root account. If your MFA device is lost, damaged, stolen or not working, you can sign in using alternative factors of authentication, deactivate the MFA device, and activate a new MFA device. As a security best practice, we recommend that you change your root account’s password. If you need a new MFA device, you can purchase a new MFA device from a third-party provider, Yubico or Gemalto, or provision a new virtual MFA device under your account by using the IAM console. If you have tried the preceding approaches and are still having trouble signing in, contact AWS Support. What is MFA-protected API access? MFA-protected API access is optional functionality that lets account administrators enforce additional authentication for customer-specified APIs by requiring that users provide a second authentication factor in addition to a password. Specifically, it enables administrators to include conditions in their IAM policies that check for and require MFA authentication for access to selected APIs. Users making calls to those APIs must first get temporary credentials that indicate the user entered a valid MFA code. What problem does MFA-protected API access solve? Previously, customers could require MFA for access to the AWS Management Console, but could not enforce MFA requirements on developers and applications interacting directly with AWS service APIs. MFA-protected API access ensures that IAM policies are universally enforced regardless of access path. As a result, you can now develop your own application that uses AWS and prompts the user for MFA authentication before calling powerful APIs or accessing sensitive resources. Which services does MFA-protected API access work with? MFA-protected API access is supported by all AWS services that support temporary security credentials. For a list of supported services, see AWS Services that Work with IAM and review the column labeled Supports temporary security credentials. Does MFA-protected API access control API access for AWS root accounts? No, MFA-protected API access only controls access for IAM users. Root accounts are not bound by IAM policies, which is why we recommend that you create IAM users to interact with AWS service APIs rather than use AWS root account credentials. Q. Is MFA-protected API access compatible with S3 objects, SQS queues, and SNS topics? Yes. Does MFA-protected API access work for federated users? Customers cannot use MFA-protected API access to control access for federated users. The GetFederatedSession API does not accept MFA parameters. Since federated users can’t authenticate with AWS MFA devices, they are unable to access resources designated using MFA-protected API access. Cross Account access - This allows you to switch between AWS accounts or AWS roles without having to sign in/out with usernames and passwords for each account again and again. You need to create a role and attach a policy for the AWS service to be accessed in one account. The role should be a "role for cross account access" that will contain the account ID of the other account. In the other account, you need to create and attach a policy for the user/group to call the role in the other account, in order to access that service. Security Token Service (STS)/Temporary Security Credentials: Grants users limited and temporary access to AWS resources. Users can come from three sources - Federation (typically Active Directory) - Uses Security Assertion Markup language (SAML). It grants users access based on their active directory credentials even if they are not IAM users. Single sign on allows them access to AWS resources, without assigning them IAM credentials. Federation using mobile apps such as facebook, google, amazon or other Open ID provider. Cross account access - allows users from one account to access services from another AWS account. Key terms for STS Federation - Combining or joining a list of users from one domain (eg. IAM) to a list of users from another domain (such as Active Directory) Identity Broker - A service that allows you to take an identity from point A and join it (federate it) to point B. Identity store - Services like AD, facebook, google etc. Identities - A user of a service like facebook See picture 1-3 below on how STS works. Remember that the STS service returns four things to the identity broker - Access key Secret access key Token Duration for validity of the token (1 to 36 hours) See pic 4 - imp points Q: What are temporary security credentials? Temporary security credentials consist of the AWS access key ID, secret access key, and security token. Temporary security credentials are valid for a specified duration and for a specific set of permissions. Temporary security credentials are sometimes simply referred to as tokens. Tokens can be requested for IAM users or for federated users you manage in your own corporate directory. What are the benefits of temporary security credentials? Temporary security credentials allow you to: Extend your internal user directories to enable federation to AWS, enabling your employees and applications to securely access AWS service APIs without needing to create an AWS identity for them. Request temporary security credentials for an unlimited number of federated users. Configure the time period after which temporary security credentials expire, offering improved security when accessing AWS service APIs through mobile devices where there is a risk of losing the device. Q: Can a temporary security credential be revoked prior to its expiration? No. When requesting temporary credentials, we recommend the following: When creating temporary security credentials, set the expiration to a value that is appropriate for your application. Because root account permissions cannot be restricted, use an IAM user and not the root account for creating temporary security credentials. You can revoke permissions of the IAM user that issued the original call to request it. This action almost immediately revokes privileges for all temporary security credentials issued by that IAM user Q: Can I reactivate or extend the expiration of temporary security credentials? No. It is a good practice to actively check the expiration and request a new temporary security credential before the old one expires. This rotation process is automatically managed for you when temporary security credentials are used in roles for EC2 instances. Q: Can I restrict the use of temporary security credentials to a region or a subset of regions? No. You cannot restrict the temporary security credentials to a particular region or subset of regions, except the temporary security credentials from AWS GovCloud (US) and China (Beijing), which can be used only in the respective regions from which they originated. Q: Can federated users access AWS APIs? Yes. You can programmatically request temporary security credentials for your federated users to provide them secure and direct access to AWS APIs. Q: Can federated users access the AWS Management Console? Yes. In 2 ways. Using either approach allows a federated user to access the console without having to sign in with a user name and password. by programmatically requesting temporary security credentials (such as GetFederationToken or AssumeRole) for your federated users and including those credentials as part of the sign-in request to the AWS Management Console you can post a SAML assertion directly to AWS sign-in (https://signin.aws.amazon.com/saml). The user’s actions in the console are limited to the access control policy associated with the IAM role that is assumed using the SAML assertion. Q: How do I control what a federated user is allowed to do when signed in to the console? When you request temporary security credentials for your federated user using an AssumeRole API, you can optionally include an access policy with the request. The federated user’s privileges are the intersection of permissions granted by the access policy passed with the request and the access policy attached to the IAM role that was assumed. The access policy passed with the request cannot elevate the privileges associated with the IAM role being assumed. Q: How do I control how long a federated user has access to the AWS Management Console? Depending on the API used to create the temporary security credentials, you can specify a session limit between 15 minutes and 36 hours (for GetFederationToken and GetSessionToken) and between 15 minutes and 12 hours (for AssumeRole* APIs), during which time the federated user can access the console. When the session expires, the federated user must request a new session by returning to your identity provider, where you can grant them access again Q: How many federated users can I give access to the AWS Management Console? There is no limit to the number of federated users who can be given access to the console. Q: Are there any default quota limits associated with IAM? Yes, by default your AWS account has initial quotas set for all IAM-related entities. IAM Best Practices: Lock Away Your AWS Account Root User Access Keys If you don't already have an access key for your AWS account root user, don't create one unless you absolutely need to. Instead, use your account email address and password to sign in to the AWS Management Console and create an IAM user for yourself that has administrative permissions. If you do have an access key for your AWS account root user, delete it. If you must keep it, rotate (change) the access key regularly. To delete or rotate your root user access keys, go to the Security Credentials page in the AWS Management Console and sign in with your account's email address and password. Enable AWS multi-factor authentication (MFA) on your AWS account root user account. Create Individual IAM Users - Don't use your AWS account root user credentials to access AWS, and don't give your credentials to anyone else. Instead, create individual users for anyone who needs access to your AWS account. Create an IAM user for yourself as well, give that user administrative permissions, and use that IAM user for all your work. Use Groups to Assign Permissions to IAM Users Grant Least Privilege - When you create IAM policies, follow the standard security advice of granting least privilege, or granting only the permissions required to perform a task. Determine what users need to do and then craft policies for them that let the users perform only those tasks. Start with a minimum set of permissions and grant additional permissions as necessary. Doing so is more secure than starting with permissions that are too lenient and then trying to tighten them later. One feature that can help with this is service last accessed data. View this data on the Access Advisor tab on the IAM console details page for a user, group, role, or policy. You can also use the AWS CLI or AWS API to retrieve service last accessed data. This data includes information about which services a user, group, role, or anyone using a policy attempted to access and when. You can use this information to identify unnecessary permissions so that you can refine your IAM policies to better adhere to the principle of least privilege. To further reduce permissions, you can view your account's events in CloudTrail Event history. CloudTrail event logs include detailed event information that you can use to reduce the policy's permissions and include only the actions and resources that your IAM entities need. Get Started Using Permissions With AWS Managed Policies Use Customer Managed Policies Instead of Inline Policies - For custom policies, we recommend that you use managed policies instead of inline policies. A key advantage of using these policies is that you can view all of your managed policies in one place in the console. You can also view this information with a single AWS CLI or AWS API operation. Inline policies are policies that exist only on an IAM identity (user, group, or role). Managed policies are separate IAM resources that you can attach to multiple identities. If you have inline policies in your account, you can convert them to managed policies. Use Access Levels to Review IAM Permissions - To improve the security of your AWS account, you should regularly review and monitor each of your IAM policies. Make sure that your policies grant the least privilege that is needed to perform only the necessary actions. When you review a policy, you can view the policy summary that includes a summary of the access level for each service within that policy. AWS categorizes each service action into one of four access levels based on what each action does:List, Read,Write, or Permissions management. You can use these access levels to determine which actions to include in your policies. Configure a Strong Password Policy for Your Users Enable MFA for Privileged Users Use Roles for Applications That Run on Amazon EC2 Instances - Applications that run on an Amazon EC2 instance need credentials in order to access other AWS services. To provide credentials to the application in a secure way, use IAM roles. A role is an entity that has its own set of permissions, but that isn't a user or group. Roles also don't have their own permanent set of credentials the way IAM users do. In the case of Amazon EC2, IAM dynamically provides temporary credentials to the EC2 instance, and these credentials are automatically rotated for you. Use Roles to Delegate Permissions - Don't share security credentials between accounts to allow users from another AWS account to access resources in your AWS account. Instead, use IAM roles. You can define a role that specifies what permissions the IAM users in the other account are allowed. You can also designate which AWS accounts have the IAM users that are allowed to assume the role. Do Not Share Access Keys - Access keys provide programmatic access to AWS. Do not embed access keys within unencrypted code or share these security credentials between users in your AWS account. For applications that need access to AWS, configure the program to retrieve temporary security credentials using an IAM role. To allow your users individual programmatic access, create an IAM user with personal access keys. Rotate Credentials Regularly Remove Unnecessary Credentials - Remove IAM user credentials (passwords and access keys) that are not needed. For example, if you created an IAM user for an application that does not use the console, then the IAM user does not need a password. Similarly, if a user only uses the console, remove their access keys. Passwords and access keys that have not been used recently might be good candidates for removal. Use Policy Conditions for Extra Security - To the extent that it's practical, define the conditions under which your IAM policies allow access to a resource. For example, you can write conditions to specify a range of allowable IP addresses that a request must come from. You can also specify that a request is allowed only within a specified date range or time range. You can also set conditions that require the use of SSL or MFA (multi-factor authentication). For example, you can require that a user has authenticated with an MFA device in order to be allowed to terminate an Amazon EC2 instance. Monitor Activity in Your AWS Account - Can be done by using logging features on - Amazon cloudfront Cloudtrail Cloudwatch AWS Config Amazon S3 AWS Cloudtrail: Web service that records API calls made on your account and delivers log files to your Amazon S3 bucket. It provides visibility into your account activity and helps ensure compliance with internal policies and regulatory standards. Cloudtrail records the following - Name of API Identity of the caller Time of the API call Request parameters Response elements returned by the AWS cloud service Cloudtrail supports log file integrity, which means you can prove to third parties (eg. auditors) that log files sent by AWS CloudTrail as not been altered. This feature is built using industry standards : SHA-256 for hashing and SHA-256 with RSA for digital signing. This makes it computationally unfeasible to modify, delete and forge AWS CloudTrail log files without detection. Read exam essentials from book
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Page 2
Amazon Elastic Cloud Compute (EC2)
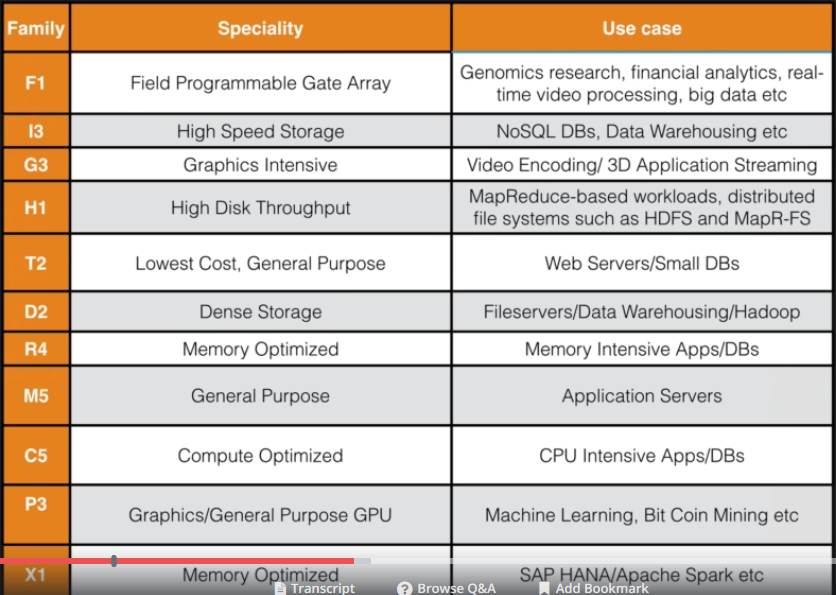
Two key concepts to launching an EC2 instance - Instance type - The amount of virtual hardware dedicated to the instance. This virtual hardware includes - Virtual CPUs (vCPUs) Memory Network Performance Storage (Size and Type) Instance types are grouped into families based on ratio of the values of the above parameters to each other. Within each family are several choices that scale up linearly in size. For eg. m4.xlarge instance costs twice as much as m4.large instance because the ratio of vCPU to memory is twice for the former. Note that m4 is the most balanced instance type in terms of all the above parameters. See pic below for all instance types. AMI type - The type of software loaded on the instance. All AMIs are based on x86 OSs including 32 and 64 bit. An AMI includes every aspect of the software state at instance launch including - 1. OS and its configuration 2. Initial state of the patches 3. Application or system software Network performance is another key parameter to consider while choosing AMI type. Network performance is categorized for AMIs as high, medium and low. For workloads requiring high network performance (10 Gbps and above), many instance types support "enhanced networking". Enhanced networking reduces the impact of virtualization on network performance by enabling the capability called "Single Root I/O virtualization" This results in more pps., less latency and less jitter. You need to modify an instance attribute to enable enhanced networking for the instance. Enhanced networking is only available for instances launched within a VPC and not for classix-EC2 instances. Sources of AMIs - Published by AWS - These are windows (2008, 2012) or linux (Red Hat, Ubuntu, AWS's own version) AMIs published by AWS. You should immediately apply all patches after launch of these instances AWS marketplace - Online store where customers can purchase software and services from other vendors, that work on AWS platform. Provides two benefits - 1. customer does not need to install the software, 2. the license agreement is appropriate for the cloud. Generated from other EC2 instances - Very common use. Good use case is where corporates need to generate EC2 instances to conform to standards Uploaded virtual servers - Using AWS VM export/import service, images can be created from various virtual formats - VHD, VMDK and OVA. For EC2 instances generated this way, it is important for the customer to remain compliant with the licensing terms of the OS vendor. If you have purchased an instance type and you want to change the reservation, only the following parameters can be changed - Moving to another AZ in the same region Changing to another instance in the same instance type family (e.g - M3 to M4 cannot be done) Addressing an instance - This can be done in 3 ways - Public DNS name - AWS automatically generates a public DNS name when an instance is launched (cannot be specified by the customer). The DNS name only persists when the instance is running and cannot be transferred to another instance. Public IP - This address is assigned from addressed reserved by AWS and cannot be specified by the customer. The IP persists while the instance is running and cannot be transferred to another instance Elastic IP - The IP persists till the customer releases it and is not linked to the lifetime or state of an instance. Because it can be transferred to a replacement EC2 in the event of an instance failure, the public address can be shared publically without coupling clients to a particular instance. It is like a static IP assigned to your AWS account. By default, one AWS account can have a maximum of 5 elastic IPs. Initial access to an instance - AWS uses public key cryptography to encrypt and decrypt login information. This technique uses a public key to encrypt the data and a private key to decrypt the data. The public and private keys are called a key pair. AWS stores the public key and the private key is stored by the customer. The private key is essential to acquiring secure access to an instance for the first time. When you launch a Windows Server, the default username is administrator. To get the password, you need to click on get windows password option on the EC2 in the dashboard. On clicking this, it will ask you for to upload your key pair and will generate a password, when you click on decrypt password. When a new Linux instance is launched, the public key is stored in the ~/.ssh/authorized_keys file and an initial user is created. Security groups - Virtual firewalls that allow controlling traffic in/out of your instance based on - Source/destination - This can be a CIDR block or another security group (this helps in decoupling SGs with specific IPs) Port Protocol Security groups have a default deny for all inbound traffic and default allow for all outbound traffic. There are two types of security groups - EC2-Classic SG - Control outgoing instance traffic VPC SG - Control outgoing and incoming instance traffic When there are more than one security groups associated with an instance, then all rules are aggregated Bootstrapping - Process of providing code to be run on an instance before it is launched. Code is entered into the UserData field of the instance launch page. UserData string is a value that is passed to the OS to be executed as a part of the launch process the first time the instance is booted. Userdata is not encrypted, so it is important that we don't include any passwords or secret keys in this On Linux this is a bash script (starts with #! and follwed by the interpreter /bin/bash) On Windows, this is a batch script or a power shell script. Can be used for applying patches and updates to the OS, enrolling in the directory service, installing application software, copying a longer program or script from storage to be run on the instance, installing chef or puppet and assigning a role VM Import/Export - Enables to easily import VMs from your existing environment as an Amazon EC2 instance and export them back to your on-prem environment. You can only export previously imported EC2 instances. Instances launched within AWS from AMIs cannot be exported Instance Metadata - Data about your instance that you can use to configure and manage your running instance. This is not user data It is a mechanism to obtain following information about your instance from the OS without making a call to the AWS API Http call to http://169.254.169.254/latest/metadata is used to return the top node of the instance metadata tree Information that this provides includes - Security groups associated with the instance Instance ID Instance type AMI used to launch the instance Public IP For eg. if you need a public IP address of an EC2 instance - you can use - curl http://169.254.169.254/latest/metadata wget http://169.254.169.254/latest/metadata You can apply upto 10 tags per instance Modifying instances - Following aspects of an instance can be modified after launch - Instance type - Can be resized/type of instance changed using AWS CLI, Console and API You need to set the instance state to STOP, change to the desired instance type and restart the instance Security groups - For instances inside a VPC, you can change the security group while an instance is running For instances inside a classic-EC2, you need to stop the instance before changing the security group Termination Protection - If termination protection is enabled, you cannot terminate an instance from the console, CLI or API. This is to prevent accidental termination of EC2 instances due to man error. Exceptions - Cannot prevent termination triggered by an OS shutdown command Cannot prevent shutdown from an auto scaling group Termination of a spot instance when the spot price changes. EC2 Pricing options - On demand - Pricing is based on hours of usage - hours for windows, seconds for linux Most flexible pricing option with no up-front committment Least cost effective option in terms of other compute per hour pricing options Reserved Instances - Allows customer to make capacity reservations in advance on a 1 year or 3 year term Cost savings of upto 75% (3 year term) on the on-demand pricing Useful for predictable workloads Customer specifies the instance types and the AZ while purchasing a reservation Two factors that determine the pricing for reserved instances - Commitment (1 year or 3 years) and payment options (3 types- see below) - All upfront - All payment in advance, no monthly charges for customer. Most economical option Partial upfront - Partial upfront payment and rest in monthly installments No upfront - All in monthly installment 3 types of reserved instances - Standard RIs: These provide the most significant discount (up to 75% off On-Demand) and are best suited for steady-state usage. Convertible RIs: These provide a discount (up to 54% off On-Demand) and the capability to change the attributes of the RI as long as the exchange results in the creation of Reserved Instances of equal or greater value. Like Standard RIs, Convertible RIs are best suited for steady-state usage. Some examples of what you can change - You can change the AZ (within the same region), change between EC2-VPC and Classic-EC2 and change instance type (as long as new instance has same or higher hourly rate) Scheduled RIs: These are available to launch within the time windows you reserve. This option allows you to match your capacity reservation to a predictable recurring schedule that only requires a fraction of a day, a week, or a month. Spot Instances -With spot instances, customers specify the price that they are willing to pay for a certain kind of instance. If the bid price is more than the current spot price, they will receive the instances. For workloads that are not time critical and tolerant to interruption Offer the greatest discount Instances will run until - The customer terminates them The spot price goes above the customer's bid price There is not enough unused capacity to meet the demand for Spot instances Use cases - Analytics, Financial modelling, big data, media encoding, scientific computing and testing (i.e any workloads that can tolerate interruption) If amazon needs to terminate a spot instance, it gives a 2 min warning before terminating it. You cannot encrypt root volumes on a standard AMI. Other volumes can be encrypted Tenancy options for EC2 - Shared tenancy - Default tenancy model Single host machine will host EC2s for various customers AWS does not use over provisioning and fully isolates instances from other instances on the same host Dedicated Instances - Dedicated instances run on hardware dedicated to a single customer Other instances in the account (those not designated as dedicated) will run in shared tenancy and will be isolated at hardware level from the dedicated instances in the account. Dedicated host - Physical server dedicated to a single customer Helps address licensing and regulatory requirements Helps customer reduce licensing costs by allowing them to use their existing server bound software licenses Customer has complete control over which specific host the instance runs as launch. This differs from dedicated instance in a way such that in dedicated instance, AWS can launch the instance on any host that is reserved for that customer's account. Supports two billing models - On demand (hourly) Reserved (upto 70% cheaper) Placement groups - A logical grouping on instances within the same AZ. Enables applications to participate in low latency - 10 Gbps network Recommended for applications that benefit from low network latency, high network throughput or both To fully use this network performance for your placement group, choose an instance type that supports enhanced networking and 10 Gbps network performance. The name that you specify for a placement group should be unique in your AWS account. Only certain types of instances can be launched in a placement group (Compute optimized, GPU, Memory optimized, Storage Optimized. AWS recommends that instances within a placement group be homogeneous in terms of size and type Placement Groups cannot be merged You cannot move an existing, running instance to a placement group. You can create an AMI from the instance and launch a new instance from the AMI, in the placement group Two types of placement groups - Cluster placement groups - A cluster placement group is a logical grouping of instances within a single Availability Zone. A placement group can span peered VPCs in the same region. The chief benefit of a cluster placement group, in addition to a 10 Gbps flow limit, is the non-blocking, non-oversubscribed, fully bi-sectional nature of the connectivity. In other words, all nodes within the placement group can talk to all other nodes within the placement group at the full line rate of 10 Gpbs flows and 25 aggregate without any slowing due to over-subscription. Cluster placement groups are recommended for applications that benefit from low network latency, high network throughput, or both, and if the majority of the network traffic is between the instances in the group. To provide the lowest latency and the highest packet-per-second network performance for your placement group, choose an instance type that supports enhanced networking. Used for big data processing (Casandra). T2 micro and T3 nano cannot be part of a cluster placement group Spread placement group - A spread placement group is a group of instances that are each placed on distinct underlying hardware. Spread placement groups are recommended for applications that have a small number of critical instances that should be kept separate from each other. Launching instances in a spread placement group reduces the risk of simultaneous failures that might occur when instances share the same underlying hardware. Spread placement groups provide access to distinct hardware, and are therefore suitable for mixing instance types or launching instances over time.
{kind=link}
{kind=link}
Page 3
Amazon Elastic Block Storage (EBS)
You can select your AMIs based on - Region OS Architecture (32 bit or 64 bit) Launch permissions Storage for the root device (Root device volume) - These are of two types - Instance Stores (Ephemeral storage) - The root device for an instance launched from an AMI is an instance store volume created from a template stored in Amazon S3. This is a temporary block level storage and is located on disks that are physically attached to the host computer. It can only be added before launching the EC2. You cannot stop an instance with an instance store - you can only reboot or terminate it, which means that if the underlying host/hardware fails, you will lose the instance - less durable. Instance store volume takes more time to provision than EBS volume. The instance type determines the type of hardware for the instance store volumes. While some provide HDD, some provide SSDs to provide very high random I/O performance. Not all types of instances support an instance store volume. While an instance store volume will lose data if the instance is stopped or terminated, it will persist data if the instance is just rebooted. EBS backed volumes/EBS root volumes - The root device launched from the AMI is an Amazon EBS volume created from an EBS snapshot. It can be launched before or after launching the EC2. You can stop the instance with an EBS as root volume and restart it on another host/hardware in case of the underlying host failure. More durable. This takes less time to provision By default, both types of volumes will be deleted when you terminate the associated instance. However, you can prevent the EBS volume to be deleted with the EC2 instance termination if you chose to uncheck the delete on termination option. Elastic Block store basics - Provides persistent block level storage volumes for use with EC2 instances Each EBS volume is automatically replicated within its AZ to protect you from component failure and provide high availability and durability. Multiple EBS volumes can be attached to an EC2, however one EBS volume can only be attached to one single EC2 EBS volume has to be in the same AZ as the instance that will use the volume To identify the root volume for an EC2, look in the snapshot field on the AWS management console and you will see a snapshot name in this field only for the root volume Size and type of the EBS volume can be changed on the fly, with no downtime EBS volumes can be stopped, but data on the volumes will persist, unlike Instance stores which cannot be stopped - if you stop them, you will lose data EBS backed data = Store data long term Types of EBS volumes - Magnetic Volumes Lowest cost per Gigabyte, but comes with lowest performance characteristics as well Volume size can range from 1GB to 1TB Average IOPS = 100, but can burst to hundreds of IOPs Maximum throughput = 40 to 90 MB Use cases - Cold Workloads where data is accessed infrequently, Sequential reads, situations where there is low cost storage requirement Billed based on amount of provisioned volume, regardless of how much data you store on it. General purpose Solid state device (SSD) - gp2 Cost effective storage for wide range of workloads Volume size can range from 1GB to 16TB Baseline performance of 3 IOPS per Gigabyte provisioned - capping at 10000 IOPS. eg. for 1TB volume can provide 3000 IOPS, 5TB volume cannot provide 15000 IOPS as IOPS are capped at 10000 Can burst upto 3000 IOPS for extended period of time for volumes less than 1TB. eg. for 500 GB of volume, you can get 1500 IOPS, but if you are not using entire IOPS, they are accumulated as credits. When volume gets heavy traffic, it will use these credits till the a rate of upto 3000 IOPS till credits are depleted. When the credits deplete, the IOPS will revert to 1500 IOPS Billed based on amount of provisioned volume, regardless of how much data you store on it. Use cases - wide range of workloads where very highest disk performance is not critical such as system boot volumes, small to medium databases, dev and test environments, virtual desktops Maximum throughput = 160 MB Provisioned IOS Solid state device (SSD) - io1 Most expensive EBS volume, but come with predictable I/O performance Cater to I/O intensive workloads, particularly database workloads that are sensitive to storage performance and consistency in random access I/O throughput Volume can range from 4TB to 16TB Provisioning this type of a volume requires you to specify Volume size desired number of IOPS, upto a lower of 30 times the umber of GB of volume or 20000 IOPS These volumes can be striped in RAID 0 configuration for larger size and greater performance Pricing is based on size of volume and amount of IOPS reserved - whether both are consumed or not Use cases - where you need predictable, high performance such as Critical business applications that require high IOPS performance (more than 10000 IOPS) , large database workloads Maximum throughput = 320 MB Throughput optimized HDD volumes - st1 low cost, designed for frequent access, throughput intensive workloads Volumes size can be upto 16TB Maximum IOPS = 500, maximum throughput - 500MB/s Significantly less expensive than SSD volumes Use cases - big data, data warehousing, log processing Cold HDD volumes - sc1 used for less frequently accessed workloads such as colder data needing fewer scans per day Volumes can be upto 16 TB Maximum IOPS = 250, Maximum throughput - 250MB/s Less expensive than throughput optimized volumes You can change both - volume type and volume size without any downtime i.e need to stop an instance (except for magnetic volumes) Snapshots - You can backup data on your EBS volume through point in time snapshots - incremental backups that are only taken for blocks of your volume that have changed. Snapshots can be taken through AWS console, AWS CLI, API. You can schedule these snapshots Data for the snapshot is stored on S3. Action of taking the snapshot is free, you only pay for storage. But you cannot access these snapshots in the S3 bucket like other S3 objects They are constrained by region, i.e you can use them to create new volumes, but in the same region. To create or move an EC2 instance to another AZ in the same region, you need to first take a snapshot of the volume, then create a new volume in the other AZ. If you need to create volumes in another region, you need to copy the snapshot in the other region. When you create a new volume from a snapshot, the volume is created immediately, but data is loaded lazily. This means that when the new volume is accessed, and if the data requested is not there, then it will be restored after the first request Snapshots can also be used to increase the size of an EBS volume. To increase the size, take a snapshot of the existing volume, create a new volume of the desired size with the snapshot and then replace the old volume with the new one. Snapshots of encrypted volumes are encrypted automatically You can create AMIs from snapshots Volumes created from encrypted snapshots are also encrypted automatically Snapshots can be shared only if they are not encrypted. They can be shared with other AWS accounts or publicaly To create a snapshot of a volume that serves as the root device, you need to stop the instance before taking a snapshot. The root volume gets terminated if the EC2 instance is terminated, unless the DeleteOnTermination flag is set to false. You can use Amazon Data Lifecycle Manager (Amazon DLM) to automate the creation, retention, and deletion of snapshots taken to back up your Amazon EBS volumes. Automating snapshot management helps you to: Protect valuable data by enforcing a regular backup schedule. Retain backups as required by auditors or internal compliance. Reduce storage costs by deleting outdated backups. Combined with the monitoring features of Amazon CloudWatch Events and AWS CloudTrail, Amazon DLM provides a complete backup solution for EBS volumes at no additional cost. RAID 0 and RAID 1 can be created to provide increased disk I/O When you launch an encrypted EBS volume, Amazon uses the AWS key management service (KMS) to handle key management. A new master key will be created unless you select a master key that you created separately for the service. Data and associated keys are encrypted using AES256 algorithm. Encryption is done on data as rest, as well as data in transit between the host and the storage media. Encryption is transparent so there is no impact on throughput or IOPS performance. Amazon EBS-Optimized instances – In addition to IOPS that control the performance in and out of the Amazon EBS volume, use amazon EBS optimized instances to ensure additional, dedicated capacity for Amazon EBS I/O
{kind=link}
{kind=link}
Page 4
Amazon Simple Storage Service (S3)
Block and File Storage Block storage operates at a lower level - the raw storage device level and manages data as a set of numbered, fixed size blocks. Block storage is accessed directly or via a SAN using protocols such as iSCSI and Fiberchannel. Directly attached or network attached, block storage is very closely associated to the server and operating system that is using the storage. File storage operates at upper level - at the OS level which manages data as a named hierarchy of files and folders. This type is storage is accessed directly or over a NAS using protocols such as CIFS and NFS. This type of storage is also closely associated with the server and OS that is using the storage. Amazon S3 storage is different from file or block storage as it is a cloud object storage. It is not associated to the server or OS that is using it. It functions as an independent storage.Instead of managing data as files or blocks using iSCSI, Fiber channel or NFS, it manages objects using API built on standard http verbs. Amazon S3 is - An object based strorage (to store pics, files, documents - OS cannot be installed on this type of storage). Size of files that can be uploaded - 0 bytes to 5TB Storage capacity of an S3 bucket is - Unlimited It is a reliable storage as data is spread replicated across multiple devices and facilities Files are stored in "Buckets" which are like folders on the cloud (web folders). Buckets are flat and have to file hierarchy. Buckets cannot be nested (i.e bucket within a bucket is not allowed). Nomenclature for an S3 bucket - https://"bucketname".s3.amazon.aws.com/"name of object". It is best practice to use bucket names that contain your domain name and conform to rules of DNS names. This ensures that your bucket names are your own, can be used in all regions and can host static websites. Even though the namespace for an Amazon S3 bucket is global, each Amazon S3 bucket is created in a specific region that you choose. You can create buckets in a region closer to your users to reduce latency, to fulfill data localization and compliance issues or you can create them away from your primary DC facilities for DR and business continuity needs. Data in an Amazon S3 is stored within the region unless you explicitly do cross region replication. HTTP code 200 is received after successful upload of an object to S3 Built for 99.99 availability Amazon guarantees 99.9999999% (11 nines) of durability. Provides tiered storage Provides lifecycle management, versioning, encryption It is a simple key value store which is object based. An object has the following attributes - Name Value Version ID Metadata - Is of two types - System metadata - created and used by AWS. will include date last modified, object size, md5 digest, http content type (see pic below) User metadata - is optional and can be specified by the user only at the time when the object is created. e.g - tags. It must begin with "x-amz-meta-" Sub-resources namely ACLs Torrents Nearly every AWS service uses S3 directly or indirectly. For example, Amazon S3 serves as a durable target storage for Amazon Kinesis and Amazon elastic mapReduce (Amazon EMR), it can be used as storage for Elastic block storage (EBS) and Amazon RDS snapshots or can be used as data staging and loading mechanism for Amazon RedShift and Amazon DynamoDB. Some common use cases can be - Back up and archiving on premise and cloud data Content, media and software storage and distribution Big data analytics Static website hosting Cloud native mobile and internet application hosting Disaster recovery Data can be secured in an S3 using/ Ways to control access to S3 buckets - ACLs (to secure/restrict access to individual objects or complete buckets) - not used very widely these days Bucket policies (to secure/restrict access to entire buckets) - recommended. Bucket policies include an explicit reference to the IAM principal in the policy. This principal may be associated with a different AWS account so Amazon S3 bucket policies allow you to assign cross-account access to Amazon S3 resources. Using a bucket policy, you can specify - Who can access the bucket from which subnet (CIDR block) or IP address during what time of the day Difference between a normal folder and an S3 bucket is that an S3 bucket has a unique namespace that can be accessed by a URL and resolved by a DNS (so the namespace should be globally unique i.e bucket names are global) Objects inside a bucket DO NOT inherit the tags for the bucket. Data consistency model for S3 Read after write consistency for PUTS of new objects Eventual consistency for overwrite PUTS and DELETES (i.e can take some time to propogate). In all cases updates to a single key are atomic, i.e you will either get new data or old data, but never an inconsistent mix of data. Amazon S3 API supports the following operations - Create/Delete a bucket Write an object Read an object delete an object List keys in a bucket Native interface for Amazon S3 is the REST (Representational State Transfer) API that supports the operations mentioned above. Prefixes and Delimiters - While amazon S3 uses a flat structure in a bucket, it supports the use of prefix and delimiter parameters while listing key names. This feature helps you organize, browse and retrieve objects within a bucket hierarchically. / and \ are used as delimiters. eg. logs/2016/January/Server1.log. Used with IAM or S3 bucket policies, prefixes and delimiters also allow you to create equivalent of department subdirectories or user home directories within a single bucket, restricting or sharing access to these subdirectories as needed. S3 Storage Tiers/Classes Standard Tier Availability SLA - 99.99% Durability - 11 nines Low latency and high throughput Objects are stored redundantly across multiple devices and multiple facilities Designed to sustain loss of two facilities concurrently Used for frequently accessed data (short term or long term) S3 Infrequently accessed (S3-IA) Cheaper than standard tier and used for objects that need to be accessed less frequently Low latency and high throughput Availability SLA - 99.9% Durability - 11 nines Objects are stored redundantly across multiple devices and multiple facilities Users are charged for retrieval fee (on a per GB basis) over and above the storage fee. There is also a minimum object size of 128 KB and minimum duration of 30 days, so it is best suited for infrequently used data that is stored for longer than 30 days. S3 Infrequently accessed One Zone (also called Reduced Redundancy Storage or RRS) Cheaper than S3 IA, but least redundant Used when you do not require resiliency across multiple zones. Data is stored in only one AZ Used for objects that do not need to be accessed frequently or data that can be easily reproduced/replicated such as image thumbnails. Availability SLA - 99.5% Durability- 11 nines Users are charged for retrieval fee (on a per GB basis) over and above the storage fee 20% cheaper than S3 IA Amazon Glacier Used for archival and long term backup. Can be used as a storage class of S3 (eg. when used for lifecycle management) or as an independent archiving service. Cheaper than above Durability - 11 nines. Data is stored on multiple devices on multiple AZs. To retrieve an Amazon Glacier object, you issue a restore command using one of the S3 APIs and 3-5 hours later, the Amazon Glacier object is copied to RRS . The retore just creates a copy and the original object still stays on Glacier till explicitly deleted. Works in 3 models - Expedited - When you need data retrieval in minutes - Most expensive flavor of Glacier Standard - Less expensive than expedited, but data retrieval takes 3-5 hours Bulk - Least expensive, but data retrieval takes 5-12 hours. Not available in all regions Glacier allows upto 5% data to be retrieved from it for free every month. Anything over that that is retrieved from Glacier is charged on a per GB basis per month. Use cases - replacement of tape based backup solutions and for storage/archiving of data for audit and compliance. Data stored in Glacier is in the form of TAR (Tape archive) and ZIP files. Amazon Glacier terms - Archives - Data is stored in Glacier in the form of archives. Each archive can be upto 40 GB and glacier can have multiple archives. Archives are automatically encrypted and are immutable - i.e cannot be modified once created. Vaults - Containers for archives. Each vault can contain upto 1000 archives. Access to vaults can be controlled using IAM policies or vault access policies. Vault locks - Vault lock policies help in deploying and enforcing compliance controls for Amazon Glacier locks. If you need additional file or block storage in addition to Amazon S3, use Elastic Block storage (EBS) for EC2 instances Elastic File Storage (EFS) for network attached shared file storage using NFS protocol. S3 charges are based on - Storage (per Gig basis) No. of requests to access data on the storage Storage management pricing (charges for maintaining tags, metadata) Data transfer pricing (cross region replication of data) Transfer acceleration S3 Versioning - Used to keep versions of objects in the S3 bucket. Protects data from accidental or malicious deletion. Once turned on, it cannot be turned off - can only be suspended. Versioning is turned on at each bucket level. Stores all versions of the object (including all writes, even if you delete the object). Each version has a unique ID. Integrates with Lifecycle management rules Multi factor authentication can be added to versioning to provide an additional level of security. With this, users need additional level of authentication (temporary OTP on a hardware or virtual MFA device) to delete a version of an object or change versioning state of a bucket. Note that MFA delete can only be enabled by the root account Amazon S3 preserves existing objects anytime you perform a PUT, POST, COPY, or DELETE operation on them Pre signed URLs - All Amazon S3 buckets are private by default i.e only the creator can access their objects. The owner can share the objects with others using a pre signed URL using their own security credentials to give time limited permissions to download the objects. Pre signed URLs are valid only for a specific duration and can be used to protect against "content scraping" of web content such as media files stored on S3. You can upload files much faster to S3 by enabling multipart upload - it fragments the file, uploads fragments in parallel and assembles them together again. It provides ability to pause and resume uploads as well. Helps in improving network utilization. It is a three part process - initiate, upload parts and abort/complete. It should be generally used when the object size is over 100Mb and you must use this feature if the object size is over 5 GB. You can set an object liecycle policy on a bucket to abort incomplete multi part uploads after a specified number of days. This will minimize the storage costs associated with multi part uploads that were not completed. Range GETs - Used to download (GET) only a portion of the object in Amazon S3 or Amazon glacier. You can specify range of bytes of the object that you need to download. Cross Region replication (CRR) - Amazon Simple Storage Service (Amazon S3) offers cross-region replication, a bucket-level feature that enables automatic, asynchronous copying of objects across buckets in different AWS Regions. Buckets configured for cross-region replication can be owned by the same AWS account or by different accounts. Cross-region replication is enabled with a bucket-level configuration. You add the replication configuration to your source bucket. Any ACLs and metadata associated with the bucket also gets replicated. In the minimum configuration, you provide the following: The destination bucket, where you want Amazon S3 to replicate objects An AWS IAM role that Amazon S3 can assume to replicate objects on your behalf Versioning must be enabled on source and target buckets to do CRR When you enable CRR, only new objects created after enablement of CRR and replicated. Regions must be unique for CRR to work You cannot replicate to multiple buckets or use daisy chaining Delete markers are replicated. However individual versions with delete markers are not replicated Cross region replication is commonly used to - Reduce latency for users who are far from the original S3 bucket Store data far away from the original source for DR and compliance purposes. With CRR, you can set up replication at a bucket level, a shared prefix level, or an object level using S3 object tags. Lifecycle management - Can be used in conjunction with versioning Can be applied to current as well as previous versions Lifecycle configurations can be applied to the entire bucket or only to a few objects specified by a prefix. Following actions can be done - Transition from standard to S3-IA (min. 30 days from creation date, size should be min 128Kb) Archive to glacier from S3-IA (default is 30 days from S3-IA or if not initially moved to IA, can be straightaway moved from S3 standard to Glacier on day 1) Delete the objects permanently Within a lifecycle rule, the prefix field identifies the objects subject to the rule. To apply the rule to an individual object, specify the key name. To apply the rule to a set of objects, specify their common prefix (e.g. “logs/”). Logging - S3 server access logs can be enabled (disabled by default) and logs can be stored in the same or a different bucket. Logs can include - Requester account and IP address Bucket name Request time Action (GET, PUT, LIST etc.) Response status or error code Event Notifications - Can be sent in response to actions taken on objects uploaded/stored on S3. These notifications enable you to run workflows, send alerts or perform other actions in response to changes in objects stored in S3. Notifications are set at bucket level and can be applied to objects in the bucket as well. Notification messages can be sent through the amazon Simple Notification Service (SNS) or amazon Simple Queuing Service (SQS) or delivered directly to AWS Lambda to invoke Lambda functions. You can also set up event notifications based on object name prefixes and suffixes. For example, you can choose to receive notifications on object names that start with “images/." Cloudfront - Amazon CloudFront is a fast content delivery network (CDN) service that securely delivers data, videos, applications, and APIs to customers globally with low latency, high transfer speeds, all within a developer-friendly environment. Edge location - Location where content will be cached. These locations are not just read only. You can write/PUT an object too Origin - Origin of all files that the CDN will distribute. These can be S3 buckets, EC2 instances, Elastic Load Balancer, Route 53 Distribution - Name of the CDN which consists of a collection of edge locations. There are two types of distributions - Web distribution - Used for websites (using http) RTMP distribution - Real Time Messaging Protocol distribution is used for media streaming using RTMP (eg. Adobe flash) To use AWS Cloudfront, you first need to create a distribution, which is identified by a DNS domain name such as gsehgal81.cloudfront.net. To serve files from AWS cloudfront, you simply use the distribution domain name instead of the actual website domain name. Cloudfront also works seamlessly with any non-AWS origin server which stores original, definitive versions of your files. eg. an on premise wed server. Objects are cached for the duration of the TTL. By default, the TTL timer is 24 hrs, but you can change this timer. Minimum timer is 0 sec for web distribution and 3600 sec for RTMP. You can clear the cache before expiring of the TTL, but this service is charged. This can be done by calling the "invalidation" API which will clear the cache from all Cloudfront edge locations regardless of whether the expiration timer/TTL has expired or not. You can have multiple origins for the same cloudfront distribution You may want to restrict access to content on cloudfront to only selected users such as paid subscribers or to applications/users in your company. To restrict access to your cloudfront you can use three methods - A signed URL - The URL is valid only for a certain time period and can optionally be accessed from a certain range of IPs Signed Cookies - Require authentication via public and private key pairs Origin access identities (OAI) - To restrict access to an S3 bucket only to a special cloudfront user associated with your distribution. This is the easiest way to ensure that content in a bucket is only accessed by an Amazon cloudfront user. Use cases of cloudfront- Serving static assets (images, CSS, javascript etc. that make up a bulk of the requests) of a website Serving a whole website or web application Serving content to users who are widely distributed geographically Distributing software or other large files Serving streaming media When NOT to use Cloudfront - When most requests come from a single location When most requests come via a corporate VPN S3 Security and Encryption All newly created S3 buckets are private. They can be made public manually. All objects in a bucket are also private by dafault. S3 buckets can be configured to create access logs. These logs can be saved on another S3 bucket or another AWS account. Different encryption methods - In transit - via SSL or TLS At rest - Two types - Server Side - Three types S3 Managed keys (SSE-S3) - Encryption is managed by AWS. Each object is encrypted with a unique key, applying strong multi factor encryption and then the key itself is encrypted with a master key that is regularly rotated. Uses AES256 encryption. The encrypted data, encryption key and the master key are all stored on separate hosts to provide additional security. Key management server (KMS) managed keys (SSE-KMS) - Here AWS handles your key management system and protection for S3 while you manage the keys. Also uses AES256 encryption. It is more expensive than SSE-S3, but has additional benefits There are separate permissions for using the "envelope key" (master key) which provides additional level of control Provides an audit trail of who tried to access your S3 and when. Also provides information on failed attempts when unauthorized users try to access your S3/decrypt the data Also, AWS KMS provides additional security controls to support customer efforts to comply with PCI-DSS, HIPAA/HITECH, and FedRAMP industry requirements. Encryption with customer provided keys (SSE-C) - Customer manages the encryption keys and AWS manages the encryption/decryption Client Side - To encrypt data on the client before sending it to AWS. When using client side encryption, customer retains end to end control of encryption process including management of encryption keys. Can be done in two ways - AWS KMS managed customer master key Client side master key S3 Transfer acceleration - Utilizes the Cloudfront edge network to accelerate uploads to S3. Enables fast, secure and easy transfers of files over long distances between end users and S3 buckets. With transfer acceleration enabled on AWS, you get a unique URL where you can upload objects at the edge location which are later transferred over the AWS backbone to the S3 bucket. URL eg. cloudguru.s3-accelerate.amazonaws.com. Transfer acceleration has additional charges. To get started with S3 Transfer Acceleration enable S3 Transfer Acceleration on an S3 bucket using the Amazon S3 console, the Amazon S3 API, or the AWS CLI. After S3 Transfer Acceleration is enabled, you can point your Amazon S3 PUT and GET requests to the s3-accelerate endpoint domain name. S3 Transfer Acceleration is designed to optimize transfer speeds from across the world into S3 buckets. If you are uploading to a centralized bucket from geographically dispersed locations, or if you regularly transfer GBs or TBs of data across continents, you may save hours or days of data transfer time with S3 Transfer Acceleration. S3 Storage gateway - Connects an on-premise software appliance with a cloud based storage and provides a seamless and secure integration between the on-premise IT environment and the AWS storage infrastructure. It provides low-latency performance by caching frequently accessed data on premises, while encrypting and storing all your other data in Amazon S3 or amazon glacier. It supports industry standard storage protocols to work that work with your existing applications. Once you have installed the storage gateway and associated it with your AWS account through the activation process, you can use AWS management console to create the storage gateway option to suit your needs. It is a virtual appliance that you install in the hypervisor of your data center. It is available as a virtual machine image for VMWare ESXi or Microsoft Hyper-V. Three types of storage gateways - File Gateway - Used for flat files only which are directly stored on S3 (file based storage) Files are stored in your S3 bucket and are accessed through NFS mount points Ownership, permissions and timestamps are durably stored in S3 in the user metadata of the object associated with the file. Once objects are transferred to S3, they can be managed as native S3 objects and bucket policies can be applied directly to the objects (such as cross region replication, versioning, lifecycle management). Volume Gateway - Present your applications with disk volumes using iSCSi block protocol (block based storage) These are similar to virtual hard disks with OS or databases There are two types of volume gateways - Cached volumes - Allows customers to expand their local storage capacity to Amazon S3. All data stored in the gateway cached volume is moved to amazon S3. Only recently accessed data is retained in local storage to provide low latency. Maximum size of a single volume - 32PB. However a single gateway can support upto 32 volumes for a max storage of 1PB Point in time snapshots can be taken to backup your storage gateway. The snapshots are incremental backups that only capture changed blocks. They are compressed to minimize storage charges. All gateway cached volume data and snapshot data is transferred to Amazon S3 over SSL connections. It is encrypted at rest in S3 using S3-SSE. However, you cannot directly access this data via Amazon S3 API or the S3 console. You must access it via the storage gateway. Use case is when customers want to increase their storage capacity without increasing their storage hardware or changing storage processes. Stored Volumes - Allow storing data on on-premise storage and asynchronously backing up data to Amazon S3. Provides low latency access to data and provide off site backup Data is backed up as EBS snapshots on S3. Maximum size of single volume - 16PB. Single gateway can store upto 32 volumes with max storage of 512TB. Same concept of snapshots and incremental backups applies here, but they are stored as EBS snapshots All gateway cached volume data and snapshot data is transferred to Amazon S3 over SSL connections. It is encrypted at rest in S3 using S3-SSE. However, you cannot directly access this data via Amazon S3 API or the S3 console. You must access it via the storage gateway - same as for cached volumes. Tape gateway (Gateway Virtual Tape Libraries or VTL) - Durable and cost effective archival solution VTL interface lets you leverage your existing tape based application infrastructure to store data on virtual tape cartridges that you create on your gateway VTL. A virtual tape is analogous to a physical tape, except that it is stored on the cloud. A gateway can contain 1500 tapes/ 1PB of total tape data. Virtual tapes appear in your gateway's VTL. Virtual tapes are discovered by your backup application using its standard media inventory procedure. Supported by applications such as Netbackup, Backup Exec, Veeam etc. When your tape software ejects a tape, it is archived on a virtual tape shelf (VTS) and stored on Amazon glacier. Snowball (Was called Import/Export earlier)- Uses AWS provided shippable storage appliances shipped through UPS. Each snowball is protected through AWS KMS encryption and made physically rugged to protect and secure your data in transit. Use cases can be DC migrations to cloud where you have more data to move than you can move through an internet connection. There are three variants - Snowball (standard) - Petabyte scale data transfer in and out of AWS Addresses challenges such as high network cost of large scale data transfers, long transfer times, security concerns. Data transfer through snowball can be done at approx. 1/5 cost of using internet bandwidth. 80 TB snowball is available in all regions Provides multiple level of security - Tamper resistant enclosures AES256 encryption industry standard trusted platform module (TPM) designed for security of data in custody After completion of transfer, AWS performs software erase of the snowball appliance Snowball edge - 100 TB data transfer device Has onboard storage and compute Use cases To transfer large amounts of data in and out of AWS Temporary storage for large local datasets Supports local workloads in remote or offline locations Snowmobile - Petabyte or Exabyte levels of data transfer Upto 100PB per snowmobile transferred in a shipping container pulled by a truck It takes about 6 months and 10 snowmobiles to transfer 1 exabyte of data Snowball can - Import from S3 Export to S3 To move data from glacier, you will have to first restore data to an S3 and then import S3 Legacy import/export disk - Has an upper limit of 16TB Customers send data to AWS using their own storage devices (compatibility used to be an issue) Customers buy and maintain their own hardware devices Encryption is optional Jobs cannot be managed by AWS console Has been discontinued by AWS now Types of connectivity for snowball appliances Ethernet/RJ45 STP+ copper STP+ fiber Static Websites hosting - You can use S3 to host static web content. It is serverless Very cheap and scales automatically Static only, CANNOT host dynamic content (only html - no PHP or .net) URL format - "S3 bucket name".s3-website-"region name".amazonaws.com You need to create a DNS name in your own domain for the website using CNAME or an Amazon Route53 alias that resolves the Amazon S3 website URL. Static websites use S3 in GET intensive mode. For best performance, use amazon Cloudfront for caching layer in front of your S3 bucket. Amazon S3 doesn't automatically give a user who creates a bucket or object permission to perform other actions on that bucket or object. Therefore, in your IAM policies, you must explicitly give users permission to use the Amazon S3 resources they create. S3 Vs Glacier S3 storage - max size of object is 5TB, Glacier max size of archive is 40TB Archives in Glacier are identified by system generated IDs. Objects in S3 can be given friendly names by users. Glacier archives are automatically encrypted, while encryption is optional for objects in S3. A common pattern is to use S3 as "Blob" storage for data while keeping an index to that data in another service such as Amazon dynamoDB or Amazon RDS. S3 Restore Speed Upgrade for S3 Glacier is an override of an in-progress restore to a faster restore tier if access to the data becomes urgent. If the Amazon S3 buckets that hold the data files do not reside in the same region as your cluster, you must use the REGION parameter to specify the region in which the data is located. If the Amazon S3 buckets that hold the data files do not reside in the same region as your cluster, you must use the REGION parameter to specify the region in which the data is located. FAQs - How much data can I store in Amazon S3? The total volume of data and number of objects you can store are unlimited. Individual Amazon S3 objects can range in size from a minimum of 0 bytes to a maximum of 5 terabytes. The largest object that can be uploaded in a single PUT is 5 gigabytes. For objects larger than 100 megabytes, customers should consider using the Multipart Upload capability. How is Amazon S3 data organized? Amazon S3 is a simple key-based object store. When you store data, you assign a unique object key that can later be used to retrieve the data. Keys can be any string, and they can be constructed to mimic hierarchical attributes. Alternatively, you can use S3 Object Tagging to organize your data across all of your S3 buckets and/or prefixes. How reliable is Amazon S3? Amazon S3 gives any developer access to the same highly scalable, highly available, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites. The S3 Standard storage class is designed for 99.99% availability, the S3 Standard-IA storage class is designed for 99.9% availability, and the S3 One Zone-IA storage class is designed for 99.5% availability. All of these storage classes are backed by the Amazon S3 Service Level Agreement. Q: Where is my data stored? You specify an AWS Region when you create your Amazon S3 bucket. For S3 Standard, S3 Standard-IA, and S3 Glacier storage classes, your objects are automatically stored across multiple devices spanning a minimum of three Availability Zones, each separated by miles across an AWS Region. Objects stored in the S3 One Zone-IA storage class are stored redundantly within a single Availability Zone in the AWS Region you select. Q: What is an AWS Availability Zone (AZ)? An AWS Availability Zone is an isolated location within an AWS Region. Within each AWS Region, S3 operates in a minimum of three AZs, each separated by miles to protect against local events like fires, floods, etc. Amazon S3 Standard, S3 Standard-Infrequent Access, and S3 Glacier storage classes replicate data across a minimum of three AZs to protect against the loss of one entire AZ. This remains true in Regions where fewer than three AZs are publicly available. Objects stored in these storage classes are available for access from all of the AZs in an AWS Region. The Amazon S3 One Zone-IA storage class replicates data within a single AZ. Data stored in this storage class is susceptible to loss in an AZ destruction event. Q: How do I decide which AWS Region to store my data in? There are several factors to consider based on your specific application. You may want to store your data in a Region that… ...is near to your customers, your data centers, or your other AWS resources in order to reduce data access latencies. ...is remote from your other operations for geographic redundancy and disaster recovery purposes. ...enables you to address specific legal and regulatory requirements. ...allows you to reduce storage costs. You can choose a lower priced region to save money. Q: How much does Amazon S3 cost? With Amazon S3, you pay only for what you use. There is no minimum fee. You can estimate your monthly bill using the AWS Simple Monthly Calculator. We charge less where our costs are less. Some prices vary across Amazon S3 Regions. Billing prices are based on the location of your bucket. There is no Data Transfer charge for data transferred within an Amazon S3 Region via a COPY request. Data transferred via a COPY request between AWS Regions is charged at rates specified in the pricing section of the Amazon S3 detail page. There is no Data Transfer charge for data transferred between Amazon EC2 and Amazon S3 within the same region or for data transferred between the Amazon EC2 Northern Virginia Region and the Amazon S3 US East (Northern Virginia) Region. Data transferred between Amazon EC2 and Amazon S3 across all other regions (i.e. between the Amazon EC2 Northern California and Amazon S3 US East (Northern Virginia) is charged at rates specified on the Amazon S3 pricing page Q: How am I charged if my Amazon S3 buckets are accessed from another AWS account? Normal Amazon S3 pricing applies when your storage is accessed by another AWS Account. Alternatively, you may choose to configure your bucket as a Requester Pays bucket, in which case the requester will pay the cost of requests and downloads of your Amazon S3 data. Q: How can I control access to my data stored on Amazon S3? Customers may use four mechanisms for controlling access to Amazon S3 resources: Identity and Access Management (IAM) policies, bucket policies, Access Control Lists (ACLs), and Query String Authentication. IAM enables organizations with multiple employees to create and manage multiple users under a single AWS account. With IAM policies, customers can grant IAM users fine-grained control to their Amazon S3 bucket or objects while also retaining full control over everything the users do. With bucket policies, customers can define rules which apply broadly across all requests to their Amazon S3 resources, such as granting write privileges to a subset of Amazon S3 resources. Customers can also restrict access based on an aspect of the request, such as HTTP referrer and IP address. With ACLs, customers can grant specific permissions (i.e. READ, WRITE, FULL_CONTROL) to specific users for an individual bucket or object. With Query String Authentication, customers can create a URL to an Amazon S3 object which is only valid for a limited time Q: Can I allow a specific Amazon VPC Endpoint access to my Amazon S3 bucket? You can limit access to your bucket from a specific Amazon VPC Endpoint or a set of endpoints using Amazon S3 bucket policies. S3 bucket policies now support a condition, aws:sourceVpce, that you can use to restrict access. Q: What is Amazon Macie? Amazon Macie is an AI-powered security service that helps you prevent data loss by automatically discovering, classifying, and protecting sensitive data stored in Amazon S3. Amazon Macie uses machine learning to recognize sensitive data such as personally identifiable information (PII) or intellectual property, assigns a business value, and provides visibility into where this data is stored and how it is being used in your organization. Amazon Macie continuously monitors data access activity for anomalies, and delivers alerts when it detects risk of unauthorized access or inadvertent data leaks. Q: What checksums does Amazon S3 employ to detect data corruption? Amazon S3 uses a combination of Content-MD5 checksums and cyclic redundancy checks (CRCs) to detect data corruption. Amazon S3 performs these checksums on data at rest and repairs any corruption using redundant data. In addition, the service calculates checksums on all network traffic to detect corruption of data packets when storing or retrieving data. Q: Can I setup a trash, recycle bin, or rollback window on my Amazon S3 objects to recover from deletes and overwrites? You can use Lifecycle rules along with Versioning to implement a rollback window for your Amazon S3 objects. For example, with your versioning-enabled bucket, you can set up a rule that archives all of your previous versions to the lower-cost Glacier storage class and deletes them after 100 days, giving you a 100-day window to roll back any changes on your data while lowering your storage costs. Q: What is S3 Intelligent-Tiering? Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering) is an S3 storage class for data with unknown access patterns or changing access patterns that are difficult to learn. It is the first cloud storage class that delivers automatic cost savings by moving objects between two access tiers when access patterns change. One tier is optimized for frequent access and the other lower-cost tier is designed for infrequent access. Objects uploaded or transitioned to S3 Intelligent-Tiering are automatically stored in the frequent access tier. S3 Intelligent-Tiering works by monitoring access patterns and then moving the objects that have not been accessed in 30 consecutive days to the infrequent access tier. If the objects are accessed later, S3 Intelligent-Tiering moves the object back to the frequent access tier. This means all objects stored in S3 Intelligent-Tiering are always available when needed. There are no retrieval fees, so you won’t see unexpected increases in storage bills when access patterns change. Q: What performance does S3 Intelligent-Tiering offer? S3 Intelligent-Tiering provides the same performance as S3 Standard storage. Q: How durable and available is S3 Intelligent-Tiering? S3 Intelligent-Tiering is designed for the same 99.999999999% durability as S3 Standard. S3 Intelligent-Tiering is designed for 99.9% availability, Q: Is there a minimum duration for S3 Intelligent-Tiering? S3 Intelligent-Tiering has a minimum storage duration of 30 days, which means that data that is deleted, overwritten, or transitioned to a different S3 Storage Class before 30 days will incur the normal usage charge plus a pro-rated charge for the remainder of the 30-day minimum. Q: Is there a minimum object size for S3 Intelligent-Tiering? S3 Intelligent-Tiering has no minimum billable object size, but objects smaller than 128KB are not eligible for auto-tiering and will always be stored at the frequent access tier rate. Q: Can I have a bucket that has different objects in different storage classes? Yes, you can have a bucket that has different objects stored in S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA, and S3 One Zone-IA. Q: What charges will I incur if I change the storage class of an object from S3 Standard-IA to S3 Standard with a COPY request? You will incur charges for an S3 Standard-IA COPY request and an S3 Standard-IA data retrieval. Q: Is there a minimum storage duration charge for S3 Standard-IA? S3 Standard-IA is designed for long-lived but infrequently accessed data that is retained for months or years. Data that is deleted from S3 Standard-IA within 30 days will be charged for a full 30 days. Is there a minimum object storage charge for S3 Standard-IA? S3 Standard-IA is designed for larger objects and has a minimum object storage charge of 128KB. Objects smaller than 128KB in size will incur storage charges as if the object were 128KB. For example, a 6KB object in S3 Standard-IA will incur S3 Standard-IA storage charges for 6KB and an additional minimum object size fee equivalent to 122KB at the S3 Standard-IA storage price. Q: How am I charged for using S3 One Zone-IA storage class? Like S3 Standard-IA, S3 One Zone-IA charges for the amount of storage per month, bandwidth, requests, early delete and small object fees, and a data retrieval fee. Amazon S3 One Zone-IA storage is 20% cheaper than Amazon S3 Standard-IA for storage by month, and shares the same pricing for bandwidth, requests, early delete and small object fees, and the data retrieval fee. As with S3 Standard-Infrequent Access, if you delete a S3 One Zone-IA object within 30 days of creating it, you will incur an early delete charge. For example, if you PUT an object and then delete it 10 days later, you are still charged for 30 days of storage. Like S3 Standard-IA, S3 One Zone-IA storage class has a minimum object size of 128KB. Objects smaller than 128KB in size will incur storage charges as if the object were 128KB. For example, a 6KB object in a S3 One Zone-IA storage class will incur storage charges for 6KB and an additional minimum object size fee equivalent to 122KB at the S3 One Zone-IA storage price. : Are there differences between how Amazon EC2 and Amazon S3 work with Availability Zone-specific resources? Yes. Amazon EC2 provides you the ability to pick the AZ to place resources, such as compute instances, within a region. When you use S3 One Zone-IA, S3 One Zone-IA assigns an AWS Availability Zone in the region according to available capacity. : Can I use the Amazon S3 APIs or Management Console to list objects that I’ve archived to Amazon S3 Glacier? Yes, like Amazon S3’s other storage classes (S3 Standard, S3 Standard-IA, and S3 One Zone-IA), S3 Glacier objects stored using Amazon S3’s APIs or Management Console have an associated user-defined name. You can get a real-time list of all of your Amazon S3 object names, including those stored using the S3 Glacier storage class, using the S3 LIST API Q: Can I use Amazon Glacier direct APIs to access objects that I’ve archived to Amazon S3 Glacier? Because Amazon S3 maintains the mapping between your user-defined object name and Amazon S3 Glacier’s system-defined identifier, Amazon S3 objects that are stored using the S3 Glacier storage class are only accessible through the Amazon S3 APIs or the Amazon S3 Management Console. Q: How can I retrieve my objects that are archived in Amazon S3 Glacier and will I be notified when the object is restored? To retrieve Amazon S3 data stored in the S3 Glacier storage class, initiate a retrieval request using the Amazon S3 APIs or the Amazon S3 Management Console. The retrieval request creates a temporary copy of your data in the S3 RRS or S3 Standard-IA storage class while leaving the archived data intact in S3 Glacier. You can specify the amount of time in days for which the temporary copy is stored in S3. You can then access your temporary copy from S3 through an Amazon S3 GET request on the archived object. With restore notifications, you can now be notified with an S3 Event Notification when an object has successfully restored from S3 Glacier and the temporary copy is made available to you. The bucket owner (or others, as permitted by an IAM policy) can arrange for notifications to be issued to Amazon Simple Queue Service (SQS) or Amazon Simple Notification Service (SNS). Notifications can also be delivered to AWS Lambda for processing by a Lambda function. Q: How much data can I retrieve from Amazon S3 Glacier for free? You can retrieve 10GB of your Amazon S3 Glacier data per month for free with the AWS free tier. The free tier allowance can be used at any time during the month and applies to Amazon S3 Glacier Standard retrievals. Q: How am I charged for deleting objects from Amazon S3 Glacier that are less than 90 days old? Amazon S3 Glacier is designed for use cases where data is retained for months, years, or decades. Deleting data that is archived to Amazon S3 Glacier is free if the objects being deleted have been archived in Amazon S3 Glacier for 90 days or longer. If an object archived in Amazon S3 Glacier is deleted or overwritten within 90 days of being archived, there will be an early deletion fee. This fee is prorated. If you delete 1GB of data 30 days after uploading it, you will be charged an early deletion fee for 60 days of Amazon S3 Glacier storage. If you delete 1 GB of data after 60 days, you will be charged for 30 days of Amazon S3 Glacier storage. Q: What does it cost to use Amazon S3 event notifications? There are no additional charges for using Amazon S3 for event notifications. You pay only for use of Amazon SNS or Amazon SQS to deliver event notifications, or for the cost of running an AWS Lambda function. How secure is S3 Transfer Acceleration? S3 Transfer Acceleration provides the same security as regular transfers to Amazon S3. All Amazon S3 security features, such as access restriction based on a client’s IP address, are supported as well. S3 Transfer Acceleration communicates with clients over standard TCP and does not require firewall changes. No data is ever saved at AWS Edge Locations. Q: What if S3 Transfer Acceleration is not faster than a regular Amazon S3 transfer? Each time you use S3 Transfer Acceleration to upload an object, we will check whether S3 Transfer Acceleration is likely to be faster than a regular Amazon S3 transfer. If we determine that S3 Transfer Acceleration is not likely to be faster than a regular Amazon S3 transfer of the same object to the same destination AWS Region, we will not charge for the use of S3 Transfer Acceleration for that transfer, and we may bypass the S3 Transfer Acceleration system for that upload. Q: Can I use S3 Transfer Acceleration with multipart uploads? Yes, S3 Transfer Acceleration supports all bucket level features including multipart uploads. Q: How should I choose between S3 Transfer Acceleration and AWS Snow Family (Snowball, Snowball Edge, and Snowmobile)? The AWS Snow Family is ideal for customers moving large batches of data at once. The AWS Snowball has a typical 5-7 days turnaround time. As a rule of thumb, S3 Transfer Acceleration over a fully-utilized 1 Gbps line can transfer up to 75 TBs in the same time period. In general, if it will take more than a week to transfer over the Internet, or there are recurring transfer jobs and there is more than 25Mbps of available bandwidth, S3 Transfer Acceleration is a good option. Another option is to use both: perform initial heavy lift moves with an AWS Snowball (or series of AWS Snowballs) and then transfer incremental ongoing changes with S3 Transfer Acceleration. Q: Can S3 Transfer Acceleration complement AWS Direct Connect? AWS Direct Connect is a good choice for customers who have a private networking requirement or who have access to AWS Direct Connect exchanges. S3 Transfer Acceleration is best for submitting data from distributed client locations over the public Internet, or where variable network conditions make throughput poor. Some AWS Direct Connect customers use S3 Transfer Acceleration to help with remote office transfers, where they may suffer from poor Internet performance. Q: What are S3 object tags? S3 object tags are key-value pairs applied to S3 objects which can be created, updated or deleted at any time during the lifetime of the object. With these, you’ll have the ability to create Identity and Access Management (IAM) policies, setup S3 Lifecycle policies, and customize storage metrics. These object-level tags can then manage transitions between storage classes and expire objects in the background. Q: Why should I use object tags? Object tags are a tool you can use to enable simple management of your S3 storage. With the ability to create, update, and delete tags at any time during the lifetime of your object, your storage can adapt to the needs of your business. These tags allow you to control access to objects tagged with specific key-value pairs, allowing you to further secure confidential data for only a select group or user. Object tags can also be used to label objects that belong to a specific project or business unit, which could be used in conjunction with S3 Lifecycle policies to manage transitions to other storage classes (S3 Standard-IA, S3 One Zone-IA, and S3 Glacier) or with S3 Cross-Region Replication to selectively replicate data between AWS Regions. Note that all changes to tags outside of the AWS Management Console are made to the full tag set. If you have five tags attached to a particular object and want to add a sixth, you need to include the original five tags in that request. Q: How much do object tags cost? Object tags are priced based on the quantity of tags and a request cost for adding tags. The requests associated with adding and updating Object Tags are priced the same as existing request prices. Q: What is S3 Inventory? The S3 Inventory report provides a scheduled alternative to Amazon S3’s synchronous List API. You can configure S3 Inventory to provide a CSV, ORC, or Parquet file output of your objects and their corresponding metadata on a daily or weekly basis for an S3 bucket or prefix. You can simplify and speed up business workflows and big data jobs with S3 Inventory. You can also use S3 inventory to verify encryption and replication status of your objects to meet business, compliance, and regulatory needs. Q: How much does it cost to use S3 Lifecycle management? There is no additional cost to set up and apply Lifecycle policies. A transition request is charged per object when an object becomes eligible for transition according to the Lifecycle rule. Refer to the S3 Pricing page for pricing information. Q: Can I use CRR with S3 Lifecycle rules? Yes, you can configure separate S3 Lifecycle rules on the source and destination buckets. For example, you can configure a lifecycle rule to migrate data from the S3 Standard storage class to the S3 Standard-IA or S3 One Zone-IA storage class or archive data to S3 Glacier on the destination bucket. Q: Can I use CRR with objects encrypted by AWS Key Management Service (KMS)? Yes, you can replicate KMS-encrypted objects by providing a destination KMS key in your replication configuration. Q: Are objects securely transferred and encrypted throughout replication process? Yes, objects remain encrypted throughout the CRR process. The encrypted objects are transmitted securely via SSL from the source region to the destination region. Q: Can I use CRR across AWS accounts to protect against malicious or accidental deletion? Yes, you can set up CRR across AWS accounts to store your replicated data in a different account in the target region. You can use CRR Ownership Overwrite in your replication configuration to maintain a distinct ownership stack between source and destination, and grant destination account ownership to the replicated storage. Q: What is the pricing for S3 Cross-Region Replication? You pay the Amazon S3 charges for storage (in the S3 storage class you select), COPY requests, and inter-Region data transfer for the replicated copy of data. COPY requests and inter-Region data transfer are charged based on the source Region. Storage for replicated data is charged based on the target Region. S3 bucket properties include - Versioning Server access logging Static Website hosting Object level logging Tags Transfer acceleration Events Requester pays S3 Object level properties include the S3 storage classes. This means that You can choose a storage class for an object as well when you are trying to upload it to an S3 bucket. This storage class could be different from the storage class of its bucket i.e a standard S3 bucket can have objects stored as different storage classes like standard-IA, glacier, standard -IA one zone etc.You can choose a storage class for an object as well when you are trying to upload it to an S3 bucket. This storage class could be different from the storage class of its bucket i.e a standard S3 bucket can have objects stored as different storage classes like standard-IA, glacier, standard -IA one zone etc. Cross Origin Resource sharing - Cross-origin resource sharing (CORS) defines a way for client web applications that are loaded in one domain to interact with resources in a different domain. With CORS support, you can build rich client-side web applications with Amazon S3 and selectively allow cross-origin access to your Amazon S3 resources. Cross-origin resource sharing (CORS) defines a way for client web applications that are loaded in one domain to interact with resources in a different domain. With CORS support, you can build rich client-side web applications with Amazon S3 and selectively allow cross-origin access to your Amazon S3 resources. To configure your bucket to allow cross-origin requests, you create a CORS configuration, which is an XML document with rules that identify the origins that you will allow to access your bucket, the operations (HTTP methods) that will support for each origin, and other operation-specific information. The following are example scenarios for using CORS: Scenario 1: Suppose that you are hosting a website in an Amazon S3 bucket named website as described in Hosting a Static Website on Amazon S3. Your users load the website endpoint http://website.s3-website-us-east-1.amazonaws.com. Now you want to use JavaScript on the webpages that are stored in this bucket to be able to make authenticated GET and PUT requests against the same bucket by using the Amazon S3 API endpoint for the bucket, website.s3.amazonaws.com. A browser would normally block JavaScript from allowing those requests, but with CORS you can configure your bucket to explicitly enable cross-origin requests from website.s3-website-us-east-1.amazonaws.com. Scenario 2: Suppose that you want to host a web font from your S3 bucket. Again, browsers require a CORS check (also called a preflight check) for loading web fonts. You would configure the bucket that is hosting the web font to allow any origin to make these requests. Types of URLs to access S3 bucket - Virtual hosted style - In a virtual-hosted–style URL, the bucket name is part of the domain name in the URL. For example: http://bucket.s3.amazonaws.com http://bucket.s3-aws-region.amazonaws.com. Path style URL - In a path-style URL, the bucket name is not part of the domain (unless you use a Region-specific endpoint). For example: US East (N. Virginia) Region endpoint, http://s3.amazonaws.com/bucket Region-specific endpoint, http://s3-aws-region.amazonaws.com/bucket In a path-style URL, the endpoint you use must match the Region in which the bucket resides. For example, if your bucket is in the South America (São Paulo) Region, you must use the http://s3-sa-east-1.amazonaws.com/bucket endpoint. If your bucket is in the US East (N. Virginia) Region, you must use the http://s3.amazonaws.com/bucket endpoint. Delete marker - A delete marker is a placeholder (marker) for a versioned object that was named in a simple DELETE request. Because the object was in a versioning-enabled bucket, the object was not deleted. The delete marker, however, makes Amazon S3 behave as if it had been deleted. Delete markers accrue a nominal charge for storage in Amazon S3. The storage size of a delete marker is equal to the size of the key name of the delete marker. The object named in the DELETE request is not actually deleted. Instead, the delete marker becomes the current version of the object. (The object's key name (or key) becomes the key of the delete marker.) A delete marker has a key name (or key) and version ID like any other object. However, a delete marker differs from other objects in the following ways: It does not have data associated with it. It is not associated with an access control list (ACL) value. It does not retrieve anything from a GET request because it has no data; you get a 404 error. The only operation you can use on a delete marker is DELETE, and only the bucket owner can issue such a request. Using S3 Object Lock, you can prevent an object from being deleted or overwritten for a fixed amount of time or indefinitely. S3 Object Lock provides two ways to manage object retention: retention periods and legal holds. A retention period specifies a fixed period of time during which an object remains locked. During this period, your object will be WORM-protected and can't be overwritten or deleted. A legal hold provides the same protection as a retention period, but has no expiration date. Instead, a legal hold remains in place until you explicitly remove it. S3 bucket contents are not public by default. If you want to make some objects in the S3 as public, use the object permissions to give read/write or both access to everyone (or just click on make public). However if you want to make the entire bucket or specific directories public, use a bucket policy. If you mention a principle as "*", this means any user, role, group Bucket policy editor is the text editor where you enter the bucket policy commands. Policy generator is the user friendly tool that helps you generate the JSON code to be pasted in the policy editor. When you have multiple versions of an object and you have used the GetObject permission in the bucket policy, you will only be able to view the latest version of the object. If you try to access the previous versions using the S3 object links to previous versions, you will get access denied. To get access to all previous versions, use the GetObjectVersion permission. Read Exam Essentials from book
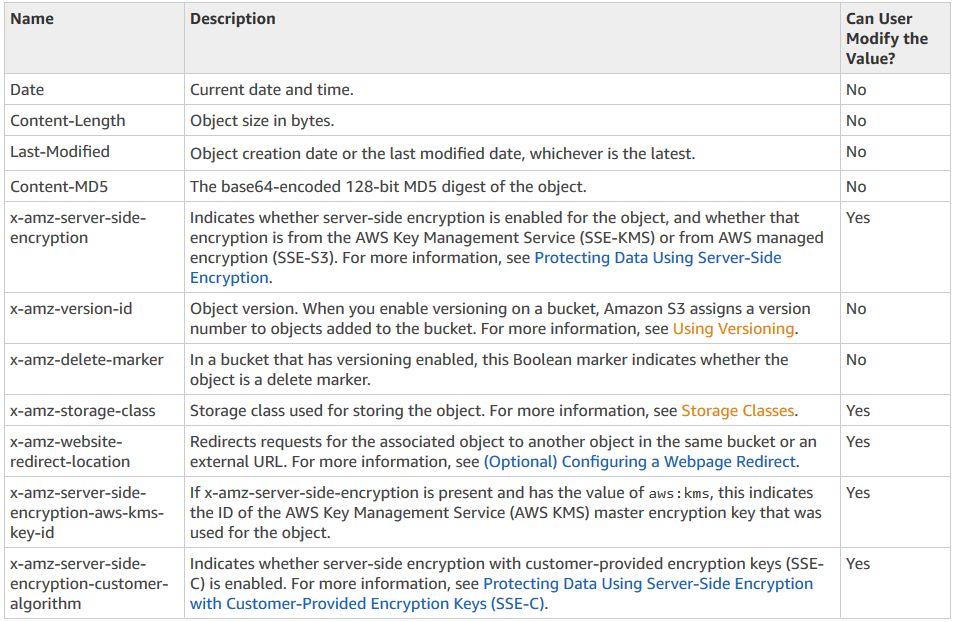{kind=link}
Page 5
Amazon Elastic File Storage (EFS)
Amazon Elastic File System (Amazon EFS) provides simple, scalable file storage for use with Amazon EC2. With Amazon EFS, storage capacity is elastic, growing and shrinking automatically as you add and remove files, so your applications have the storage they need, when they need it Amazon EFS has a simple web services interface that allows you to create and configure file systems quickly and easily. The service manages all the file storage infrastructure for you, meaning that you can avoid the complexity of deploying, patching, and maintaining complex file system configurations. It can scale upto petabytes and can support thousands of concurrent connections. Amazon EFS supports the Network File System version 4 (NFSv4.1 and NFSv4.0) protocol, so the applications and tools that you use today work seamlessly with Amazon EFS Tens, hundreds, or even thousands of Amazon EC2 instances can access an Amazon EFS file system at the same time, and Amazon EFS provides consistent performance to each Amazon EC2 instance. Amazon EFS is designed to be highly durable and highly available. The EC2 instances can access the EFS in the same region/different AZs but in the same region. With Amazon EFS, you pay only for the storage used by your file system and there is no minimum fee or setup cost. Use cases - Amazon EFS is designed to provide performance for a broad spectrum of workloads and applications, including Big Data and analytics, media processing workflows, content management, web serving, and home directories. Can be used as a central repository of files/file server. The service is designed to be highly scalable, highly available, and highly durable. Amazon EFS file systems store data and metadata across multiple Availability Zones in an AWS Region. With Amazon EFS, you pay only for the amount of file system storage you use per month. When using the Provisioned Throughput mode you pay for the throughput you provision per month. There is no minimum fee and there are no set-up charges. Provides file system access semantics - Data Consistency - Amazon EFS provides the open-after-close consistency semantics that applications expect from NFS. (Read after write consistency, just as S3) In Amazon EFS, write operations will be durably stored across Availability Zones when: An application performs a synchronous write operation (for example, using the open Linux command with the O_DIRECT flag, or the fsync Linux command). An application closes a file. File locking - Locking in Amazon EFS follows the NFSv4.1 protocol for advisory locking, and enables your applications to use both whole file and byte range locks. You need an NFS mount client or an EFS mount helper on your EC2 instance to mount an EFS mount target. Flexible IO is a benchmarking utility in Linux that is used to test and benchmark Linux IO systems. You can apply user level, file level or directory level permissions to EFS volumes EFS Performance Modes -To support a wide variety of cloud storage workloads, Amazon EFS offers two performance modes. You select a file system's performance mode when you create it. The two performance modes have no additional costs, so your Amazon EFS file system is billed and metered the same, regardless of your performance mode. An Amazon EFS file system's performance mode can't be changed after the file system has been created. Two types of performance modes - General Purpose Performance Mode - We recommend the General Purpose performance mode for the majority of your Amazon EFS file systems. General Purpose is ideal for latency-sensitive use cases, like web serving environments, content management systems, home directories, and general file serving. If you don't choose a performance mode when you create your file system, Amazon EFS selects the General Purpose mode for you by default. Max I/O Performance Mode - File systems in the Max I/O mode can scale to higher levels of aggregate throughput and operations per second with a tradeoff of slightly higher latencies for file operations. Highly parallelized applications and workloads, such as big data analysis, media processing, and genomics analysis, can benefit from this mode. Throughput modes - Two types - Bursting throughput - Throughput on Amazon EFS scales as your file system grows Provisioned Throughput - You can instantly provision the throughput of your file system (in MiB/s) independent of the amount of data stored. See pictures below FAQs Q. Are file system names global (like Amazon S3 bucket names)? Every file system has an automatically generated ID number that is globally unique. You can tag your file system with a name, and these names do not need to be unique. Q: What is Amazon EFS Encryption? Amazon EFS offers the ability to encrypt data at rest and in transit. Data encrypted at rest is transparently encrypted while being written, and transparently decrypted while being read, so you don’t have to modify your applications. Encryption keys are managed by the AWS Key Management Service (KMS), eliminating the need to build and maintain a secure key management infrastructure. Data encryption in transit uses industry standard Transport Layer Security (TLS) 1.2 to encrypt data sent between your clients and EFS file systems. Encryption of data at rest and of data in transit can be configured together or separately to help meet your unique security requirements. Note that Encryption of data at rest can only be done at the time of file system creation. Enabling encryption of data in transit for your Amazon EFS file system is done by enabling Transport Layer Security (TLS) when you mount your file system using the Amazon EFS mount helper. If you have already mounted your unencrypted EFS volume to an EC2 instance, you need to unmount it and then enable TLS encryption while mounting it again. You can enforce data encryption policies for Amazon EFS file systems by using Amazon CloudWatch and AWS CloudTrail to detect the creation of a file system and verify that encryption is enabled. How do I access my file system from outside my VPC? Amazon EC2 instances within your VPC can access your file system directly, and Amazon EC2 Classic instances outside your VPC can mount a file system via ClassicLink. Amazon EC2 instances in other VPCs can access your file system if connected using a VPC peering connection or VPC Transit Gateway. On-premises servers can mount your file systems via an AWS Direct Connect or AWS VPN connection to your VPC. How do I access a file system from an Amazon EC2 instance? To access your file system, you mount the file system on an Amazon EC2 Linux-based instance using the standard Linux mount command and the file system’s DNS name. Once mounted, you can work with the files and directories in your file system just like you would with a local file system. How do I load data into a file system? There are a number of methods for loading existing file system data into Amazon EFS, whether your existing file system data is located in AWS or in your on-premises servers. Amazon EFS file systems can be mounted on an Amazon EC2 instance, so any data that is accessible to an Amazon EC2 instance can also be read and written to Amazon EFS. To load file data that is not currently stored in AWS, you can use AWS DataSync to copy data directly to Amazon EFS. For on-premises file systems, DataSync provides a fast and simple way to securely sync existing file systems into Amazon EFS. DataSync works over any network connection, including with AWS Direct Connect or AWS VPN. AWS Direct Connect provides a high bandwidth and lower latency dedicated network connection, over which you can mount your EFS file systems. You can also use standard Linux copy tools to move data files to Amazon EFS. How do I back up a file system? Amazon EFS is designed to be highly durable. Using the EFS-to-EFS Backup solution, you can schedule automatic incremental backups of your Amazon EFS file system. Q. How many file systems can I create? The number of file systems you can create per account differs by region. What storage classes does Amazon EFS offer? Amazon EFS offers a Standard and an Infrequent Access storage class. The Standard storage class is designed for active file system workloads and you pay only for the file system storage you use per month. The EFS Infrequent Access (EFS IA) is a lower cost storage class that’s cost-optimized for less frequently accessed files. Data stored on the EFS IA storage class costs less than Standard and you pay a fee each time you read from or write to a file. EFS file systems transparently serve data from both storage classes. EFS IA reduces storage costs with savings up to 85% compared to the EFS Standard storage class. Q. When should I enable Lifecycle Management? Enable Lifecycle Management when your file system contains files that are not accessed every day to reduce your storage costs. EFS IA is ideal for EFS customers who need their full data set to be readily accessible and want to automatically save on storage costs as their files become less frequently accessed. Examples include satisfying audits, performing historical analysis, or backup and recovery. Q. What is AWS DataSync? AWS DataSync is an online data transfer service that makes it faster and simpler to move data between on-premises storage and Amazon EFS. DataSync uses a purpose-built protocol to accelerate and secure transfer over the Internet or AWS Direct Connect, at speeds up to 10 times faster than open-source tools. Using DataSync you can perform one-time data migrations, transfer on-premises data for timely in-cloud analysis, and automate replication to AWS for data protection and recovery. Q. Can EFS data be copied between regions with AWS DataSync? No, AWS DataSync does not support copying EFS data between AWS Regions. Q. How do I control who can access my file system? You can control who can administer your file system using AWS Identity and Access Management (IAM). You can control access to files and directories with POSIX-compliant user and group-level permissions. Q. What is Provisioned Throughput and when should I use it? Provisioned Throughput enables Amazon EFS customers to provision their file system’s throughput independent of the amount of data stored, optimizing their file system throughput performance to match their application’s needs. Amazon EFS Provisioned Throughput is available for applications with a high throughput to storage (MB/s per TB) ratio. For example, customers using Amazon EFS for development tools, web serving or content management applications, where the amount of data in their file system is low relative to throughput demands, are able to get the high levels of throughput their applications require without having to pad the amount of data in their file system. The default Bursting Throughput mode offers customers a simple experience and is suitable for a majority of applications with a wide range of throughput requirements such as Big Data Analytics, Media Processing workflows, Content Management, Web Serving, and Home Directories. Generally, we recommend to run your application in the default Bursting Throughput mode. If you experience performance issues check the BurstCreditBalance CloudWatch metric and determine if Provisioned Throughput is right for your application. If the value of the BurstCreditBalance metric is either zero or steadily decreasing, Provisioned Throughput is right for your application. You can create a new file system in the provisioned mode or change your existing file system’s throughput mode from Bursting Throughput to Provisioned Throughput at any time via the AWS Console, AWS CLI, or AWS API. Q. How does Amazon EFS Provisioned Throughput work? When you select Provisioned Throughput for your file system, you can provision the throughput of your file system independent of the amount of data stored and pay for the storage and Provisioned Throughput separately. (ex. $0.30 per GB-Month of storage and $6.00 per MB/s-Month of Provisioned Throughput in US-East (N. Virginia)) When you select the default Bursting Throughput mode, the throughput of your file system is tied to the amount of data stored and you pay one price per GB of storage (ex. $0.30 per GB-Month in US-East (N. Virginia)). In the default Bursting Throughput mode, you get a baseline rate of 50 KB/s per GB of throughput included with the price of storage. Provisioned Throughput also includes 50 KB/s per GB (or 1 MB/s per 20 GB) of throughput in the price of storage. For example, if you store 20 GB for a month on Amazon EFS and configure a throughput of 5 MB/s for a month you will be billed for 20 GB-Month of storage and 4 (5-1) MB/s-Month of throughput. Q. How will I be billed in the Provisioned Throughput mode? In the Provisioned Throughput mode, you are billed for storage you use and throughput you provisioned independently. You are billed hourly in the following dimensions: Storage (per GB-Month) - You are billed for the amount of storage you use in GB-Month. Throughput (per MB/s-Month) – You are billed for throughput you provision in MB/s-Month. Q. How often can I change the throughput mode or the throughput of my file system in the Provisioned Throughput mode? If your file system is in the provisioned mode, you can increase the provisioned throughput of your file system as often as you want. You can decrease your file system throughput in Provisioned Throughput mode or change between Provisioned Throughput and the default Bursting Throughput modes as long as it’s been more than 24 hours since the last decrease or throughput mode change.
{kind=link}
{kind=link}
{kind=link}
Page 6
AWS Lambda
AWS Lambda is a computer service where you can upload code and create a Lambda function. It lets you run code without provisioning or managing servers. You pay only for the compute time you consume - there is no charge when your code is not running. With Lambda, you can run code for virtually any type of application or backend service - all with zero administration. Just upload your code and Lambda takes care of everything required to run and scale your code with high availability. You can set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app. Lambda encapsulates the following and lets you do serverless computing - Datacenter Hardware Assembly code/protocols High level languages Operating systems Application layer/AWS APIs Lambda features - Let's you run code without provisioning or managing servers Triggers on your behalf in response to events Scales automatically Provides built in code for monitoring and logging using CloudWatch There are two types of permissions needed for Lambda functions - Event sources need permission to trigger a Lambda function (this is done through IAM policies to invoke the function) Execution role: - The Lambda function needs permission to interact with other AWS services (done through IAM roles). The Lambda function here will need a trust policy that gives it the AssumeRole to access other AWS services. Note that the creator of the Lambda function should have the iam:PassRole permission in order to create an execution role. Lambda and VPC - By default, Lambda functions do not have access to resources inside a private VPC, as they are created in the default VPC. To enable access to resources in a private VPC, you need to give permission the VPC subnet IDs and Security group IDs. With these permissions, the Lambda function also creates elastic network interfaces on the private VPC to be able to access the services within the VPC. The execute role mentioned above gives Lambda the permission to read, write and delete network interfaces. If you want to attach a Lambda function to resources within a private VPC, ensure that the elastic network interfaces on the VPC have enough IP address space and enough interface capacity/bandwidth. Elastic network interface capacity = (No. of concurrent executions of your Lambda code * amount of memory configured for your function in GB)/3 GB If you see no cloudwatch logs,but see an increase in the network interface errors - this would indicate an issue with the network interface capacity Lambda can be used in the following ways - As an event driven compute service where AWS Lambda runs your code in response to an events. These events could be changes to data in your S3 bucket or an Amazon DynamoDB table. There could be four types of event sources - Data stores - such as Amazon RDS Aurora, S3, Kinesis, DynamoDB, Cognito Endpoints - Alexa, IoT, Amazon step functions, Amazon API gateway Repositories- Cloudwatch, Cloudtrail, Cloudformation, Amazon Code commit Messaging Services - SNS, SQS, SES As a compute service that runs your code in response to HTTP requests using Amazon API gateway or API calls made using AWS SDKs Lambda events can trigger other Lambda functions or other AWS services such as SQS, SNS etc. Lambda triggers available can vary from region to region Types of Lambda triggers - API gateway AWS IoT Application load balancer Cloudwatch logs Cloudwatch Events Code Commit Cognito Sync trigger Kinesis SNS DynamoDB S3 SQS Types of programming languages available in Lambda- Python node.js Java C# Powershell Ruby Go Types of run-time environments/IDEs available for Lambda - AWS Cloud 9 Visual Studio Eclipse Every time a new user sends an http request to an API gateway, the API gateway will invoke a new Lambda function i.e if two users send two http requests for the same webpage, two separate Lambda functions will be invoked. While there will be separate Lambda functions invoked, the code inside the functions will be the same. Pricing - Customer is billed based on - Number of requests. First 1 million requests are free. $0.20 per 1 million requests thereafter. Duration - Duration is calculated from the time your code begins to execute till it returns or is terminated. The price depends upon the amount of memory that you have allocated to the function. The duration of the execution of the function cannot exceed 5 minutes. If the execution will be more than 5 minutes then you need to break your function into multiple functions and then get one function to invoke the next one and so on. One Lambda function can invoke more than one other Lambda function Lambda scales out (not up) automatically Serverless services in AWS API gateway Lambda S3 DynamoDB AWS X-ray helps you debug your code and see what is happening Each AWS Lambda function runs in its own isolated environment, with its own resources and file system view. AWS Lambda uses the same techniques as Amazon EC2 to provide security and separation at the infrastructure and execution levels. AWS Lambda stores code in Amazon S3 and encrypts it at rest. AWS Lambda performs additional integrity checks while your code is in use. Ways to author Lambda functions - Write in Lambda management console - Used for simple, one function applications and for experimentation Upload deployment package to Lambda management console - Used for small, standalone applications with less than 10 MB package Upload deployment package to S3 - For packages over 10MB in size that use automated CI/CD methods of deployment Core components of of configuring Lambda functions - Memory Time out Concurrency Use cases - Event driven log analysis IoT Event driven transformations Automated backups Processing objects uploaded to S3 Operating serverless websites Lambda function can access an AWS service regardless of the region, as long as it has internet access. If your Lambda function needs to access private VPC resources (for example, an Amazon RDS DB instance or Amazon EC2 instance), you must associate the function with a VPC. If your function also requires internet access (for example, to reach a public service like Amazon DynamoDB), your function must use a NAT gateway or instance. To add a VPC configuration to your Lambda function, you must associate it with at least one subnet. If the function needs internet access, you need to follow two rules: The function should only be associated with private subnets. Your VPC should contain a NAT gateway or instance in a public subnet. If a Lambda function is running in no-VPC mode, it does not have access to resources in a private VPC. Each Lambda function receives 512MB of temporary/ephemeral disck space in its own /tmp directory. For each cache behavior in a CloudFront distribution, you can add up to four triggers (associations) that cause a Lambda function to execute when specific CloudFront events occur. CloudFront triggers can be based on one of four CloudFront events - (also see pic below) Viewer Request - The function executes when CloudFront receives a request from a viewer, before it checks to see whether the requested object is in the edge cache. Origin Request - The function executes only when CloudFront forwards a request to your origin. When the requested object is in the edge cache, the function doesn't execute. Origin Response - The function executes after CloudFront receives a response from the origin and before it caches the object in the response. Note that the function executes even if an error is returned from the origin. Viewer Response - The function executes before returning the requested file to the viewer. Note that the function executes regardless of whether the file is already in the edge cache. When you update a Lambda function, there will be a brief window of time, typically less than a minute, when requests could be served by either the old or the new version of your function. Aliases - You can create one or more aliases for your Lambda function. An AWS Lambda alias is like a pointer to a specific Lambda function version. By using aliases, you can access the Lambda function an alias is pointing to (for example, to invoke the function) without the caller having to know the specific version the alias is pointing to. ARNs allowed for Lambda functions (examples) - arn:aws:lambda:aws-region:acct-id:function:helloworld:$LATEST (This is a qualified ARN with a version suffix) arn:aws:lambda:aws-region:acct-id:function:helloworld:PROD (Qualified ARN with an alias name) arn:aws:lambda:aws-region:acct-id:function:helloworld:BETA (Qualified ARN with an alias name) arn:aws:lambda:aws-region:acct-id:function:helloworld:DEV (Qualified ARN with an alias name) arn:aws:lambda:aws-region:acct-id:function:helloworld (Unqualified ARN. This cannot be used to create an alias) Cross account permissions can be added to a Lambda function using function policies Dead letter queue is available for - SQS SNS Read cloudwatch metrics for Lambda functions - https://docs.aws.amazon.com/lambda/latest/dg/monitoring-functions-metrics.html Read difference between Lambda and Beanstalk – https://acloud.guru/forums/aws-certified-solutions-architect-associate/discussion/-KTTxk7jZJWOGDZINHfd/what-is-an-difference-between-lambda-elastic-beanstack See use case pics below - See Lambda resource limits pic below
{kind=link}
{kind=link}
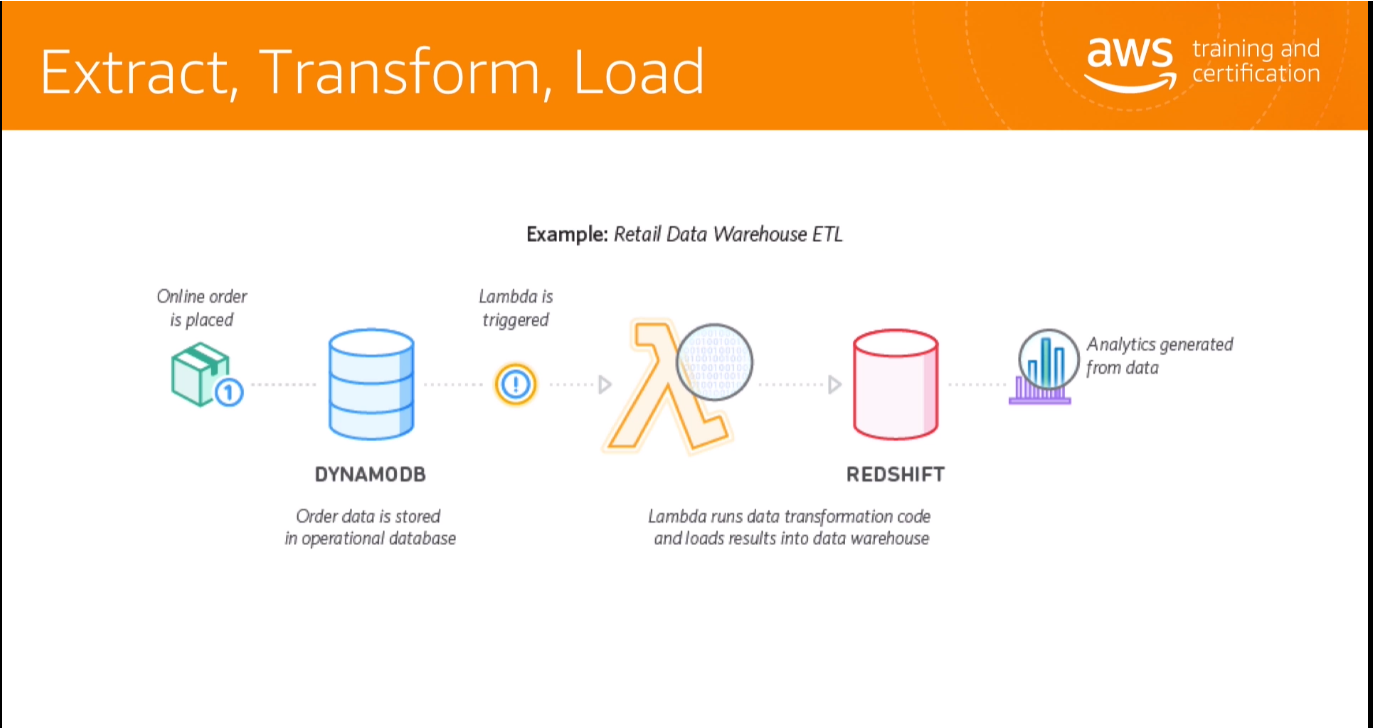{kind=link}
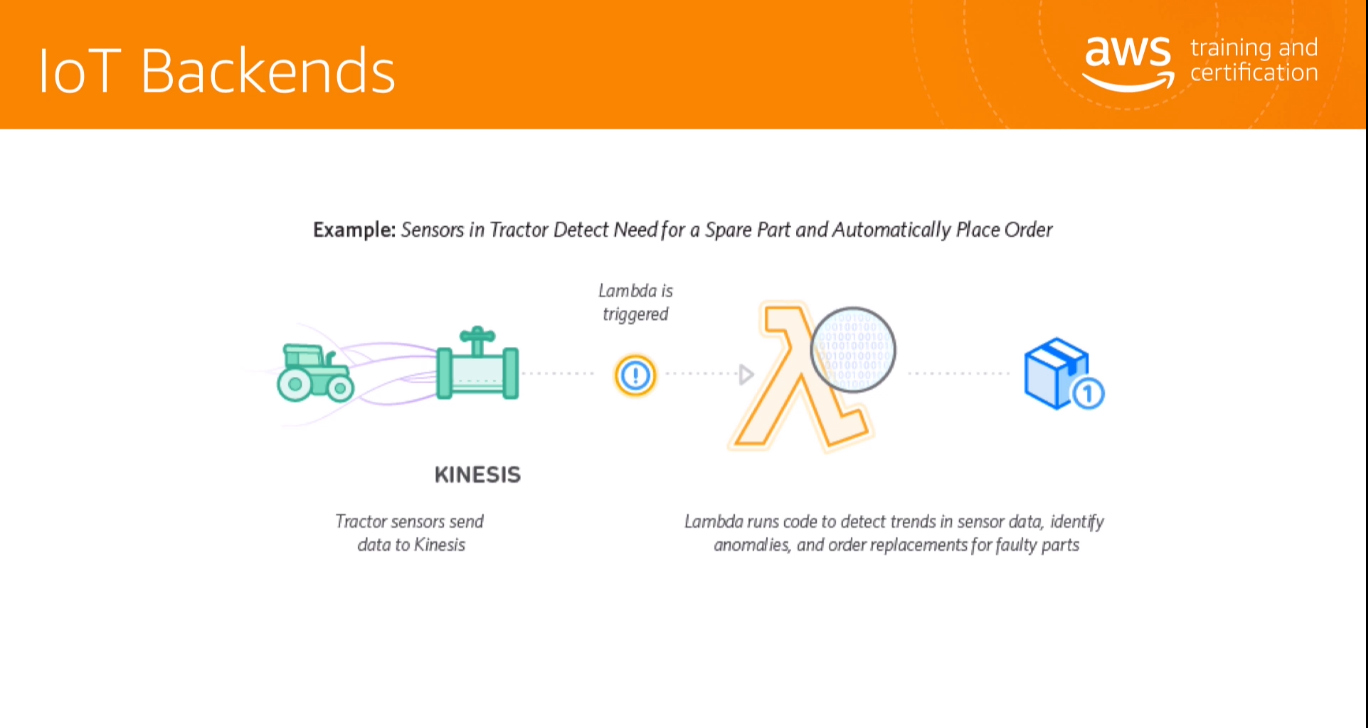{kind=link}
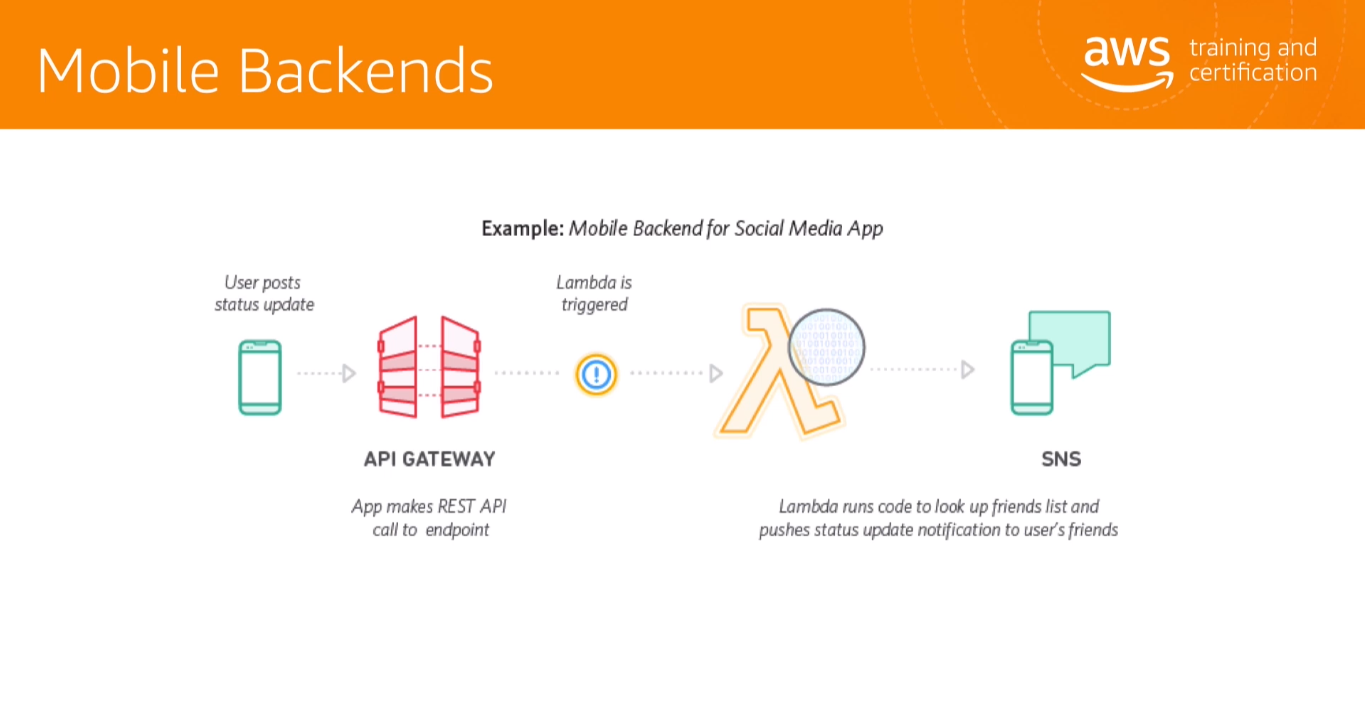{kind=link}
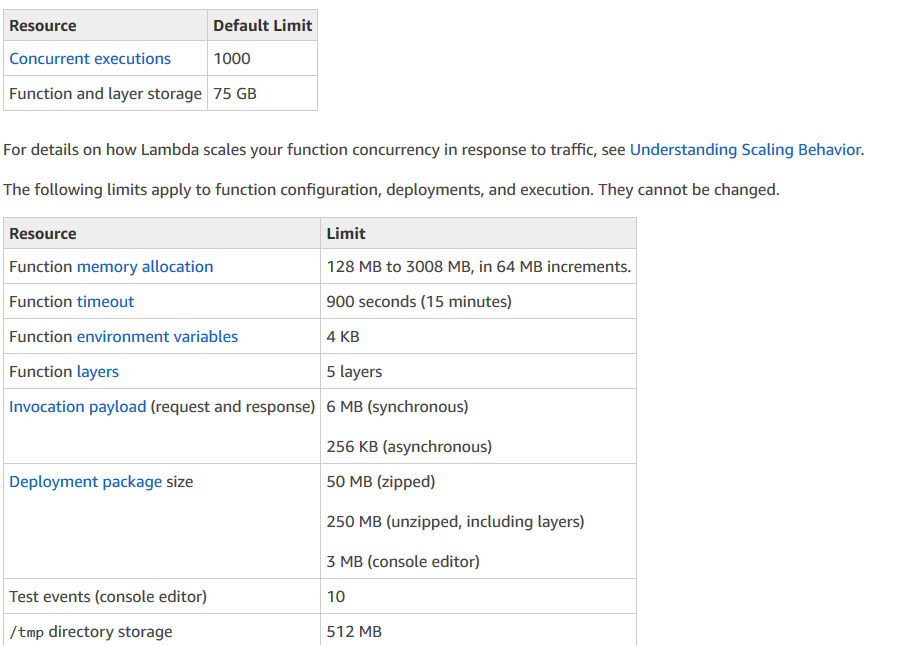{kind=link}
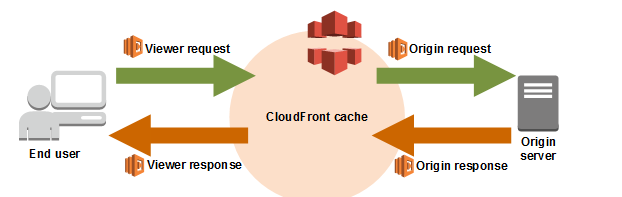{kind=link}
Page 7
Virtual Private Cloud
Virtual Private cloud (VPC) is a virtual data center in the cloud Every region where you set up AWS account has a default VPC set up for you A customer's VPC helps them have complete control of their virtual networking environment including - IP addressing Configuration of route tables and NAT gateways Creation of subnets - Public subnets for your internet facing servers such as web servers, Private subnets for your back end systems such as application servers, database servers etc, VPN subnets where the associated route table directs subnet's traffic to a virtual private gateway and does not have a route to an internet gateway. Leveraging multiple layers of security - Security groups to act as firewalls to allow/block traffic at instance level Network ACLs (NACLs) to permit/deny traffic at subnet/IP level. Within a region, you can create multiple VPCs and each Amazon VPC is logically isolated even if it shares its IP address space. IP address range of a VPC cannot be changed after the VPC is created. The range can be as large as a /8 and as small as a /28 (16 available IP addresses). By launching your instances into a VPC instead of EC2-Classic (which was used before VPCs were introduced in Dec 2013), you gain the ability to: Assign static private IPv4 addresses to your instances that persist across starts and stops Optionally associate an IPv6 CIDR block to your VPC and assign IPv6 addresses to your instances Assign multiple IP addresses to your instances Define network interfaces, and attach one or more network interfaces to your instances Change security group membership for your instances while they're running Control the outbound traffic from your instances (egress filtering) in addition to controlling the inbound traffic to them (ingress filtering) Add an additional layer of access control to your instances in the form of network access control lists (ACL) Run your instances on single-tenant hardware You can use AWS Identity and Access Management to control who in your organization has permission to create and manage security groups, network ACLs and flow logs. For example, you can give only your network administrators that permission, but not personnel who only need to launch instances Your VPC has attributes that determine whether your instance receives public DNS hostnames, and whether DNS resolution through the Amazon DNS server is supported.(see pic 2 below). If both attributes are set to true, the following occurs: Your instance receives a public DNS hostname. The Amazon-provided DNS server can resolve Amazon-provided private DNS hostnames. If either or both of the attributes is set to false, the following occurs: Your instance does not receive a public DNS hostname that can be viewed in the Amazon EC2 console or described by a command line tool or AWS SDK. The Amazon-provided DNS server cannot resolve Amazon-provided private DNS hostnames. Your instance receives a custom private DNS hostname if you've specified a custom domain name in your DHCP options set. If you are not using the Amazon-provided DNS server, your custom domain name servers must resolve the hostname as appropriate. By default, both attributes are set to true in a default VPC or a VPC created by the VPC wizard One subnet can sit in only one availability zone for a customer and cannot span Zones. However, you can have multiple subnets in one AZ. Range of private subnets allowed 10.0.0.0/8 172.16.0.0 - 172.31.255.255 (172.16.0.0/12) 192.168.0.0/16 Components of a VPC - Instances Subnets (default created) Internet gateways or VPN gateways (optional) NAT gateways or NAT instances (optional) Security groups (Default created) NACLs (default created) Route tables (default created) DHCP Option sets Elastic IPs (Optional Elastic Network Interfaces (Optional) Endpoints (Optional) Peering (Optional) Customer Gateways - CGWs and VPNs (Optional) Internet gateways - Only one per VPC Highly available (outage in one AZ will not impact functioning of the internet gateway) Performs NAT for instances that have been assigned a public IP address. It maintains the private-public IP mappings for EC2 instances. Default VPC User friendly VPC, allows you to add instances immediately, as soon as you create an new AWS account (as the deafult VPC gets created when the AWS account is created) By default, a CIDR block of 172.31.0.0/16 is assigned to this VPC. With the default VPC, a default subnet is created in each AZ of the VPC region. This is a public subnet with netmask of /20, as the default route table contains a route for this subnet to the internet gateway (internet gateway is also created by default for the default subnet) Each EC2 instance in a default subnet of the default VPC has both public and private IP addresses, as well as public and private DNS addresses. Does not have private subnets by default, but private subnets can be created by the user by creating routes for the subnets in the route table and not pointing them towards the internet gateway. You can also make the default subnets as private by removing the route for 0.0.0.0/0 traffic to the internet gateway You can use a default VPC as you would use any other VPC: Add additional non default subnets. Modify the main route table. Add additional route tables. Associate additional security groups.Update the rules of the default security group. Add VPN connections. Add more IPv4 CIDR blocks. Custom VPC Created by user. Can contain both private and public subnets Instances created in private subnet in a custom VPC will not get a public IP by default. By default, each instance that you launch into a non default subnet has a private IPv4 address, but no public IPv4 address, unless you specifically assign one at launch, or you modify the subnet's public IP address attribute. These instances can communicate with each other, but can't access the internet. Whenever you create a new VPC, the following get created by default - A default route table Default NACL Default Security group VPC Tenacy - Dedicated - Dedicated hardware, cannot be shared with other customers, very expensive Default - Multi tenant First four IP addresses and the last IP (total 5) of each subnet cannot be assigned to an instance. Eg for 10.0.0.0/24 - 10.0.0.0 - Network address 10.0.0.1 - Reserved by AWS for VPC router 10.0.0.2 - Reserved by AWS for DNS (IP address of DNS server is always the network address + 2) 10.0.0.3 - Reserved by AWS for future use 10.0.0.255 - Network broadcast address You can delete a default VPC, but you cannot launch instances until you either create a new default VPC or specify subnets in another VPC Any new subnet created in a VPC will by default associate itself with the default route table. Steps to create a new VPC Create a new VPC (include its CIDR) Create subnets Create internet gateway (for public subnets) and attach VPC to the gateway Configure route tables Associate subnets with the route tables Some noteworthy points on route tables - Each subnet must be associated with a route table, which controls the routing for the subnet. If you don't explicitly associate a subnet with a particular route table, the subnet is implicitly associated with the main route table. You cannot delete the main route table, but you can replace the main route table with a custom table that you've created (so that this table is the default table each new subnet is associated with). You can modify the default route table also. Every route table contains a local route for communication within the VPC over IPv4. If your VPC has more than one IPv4 CIDR block, your route tables contain a local route for each IPv4 CIDR block. If you've associated an IPv6 CIDR block with your VPC, your route tables contain a local route for the IPv6 CIDR block. You cannot modify or delete these routes. Each route table specifies a destination CIDR and a target. eg. 172.16.0.0/12 is targeted to the VPG. AWS uses the longest match rule to route traffic. You need to assign public or elastic IP addresses to EC2 instances for them to send/receive traffic from the internet. If your subnet setting shows "enabled"it means auto assign public IP option is turned on for that subnet in the VPC. DHCP Option sets - AWS automatically creates and associates DHCP option set to your VPC upon creation and sets two options - domain name servers (defaulted to AmazonProvidedDNS) and domain-name (defaulted to domain name of your region). To assign your own domain name to your EC2 instances, create a custom DHCP option set and assign it to your Amazon VPC. You can configure the following values within your DHCP option set - domain-name-servers - The IP addresses for upto 4 domain name servers, separated by commas. The default is AmazonProvidedDNS domain-name - Specify desired domain name (eg. mycompany.com) ntp-servers - IP addresses of upto 4 NTP servers separated by commas netbios-name-servers - IP addresses of upto 4 netbios servers separated by commas netbios-node-type - set this value to 2 Every VPC must have only one DHCP option set assigned to it. Elastic IP addresses - An Elastic IP address is a static, public IP address from the pool of public IPs that AWS maintains in a region, that you can allocate to your account and release to the pool when not needed. EIPs allow you to maintain a set of IP addresses that remain fixed while the underlying infrastructure may change over time. With an Elastic IP address, you can mask the failure of an instance or software by rapidly remapping the address to another instance in your account. Some important things to note regarding Elastic IPs - You must allocate an EIP for use within a VPCand then assign it to an instance. By default, all AWS accounts are limited to five (5) Elastic IP addresses per region. AWS encourages you to use an Elastic IP address primarily for the ability to remap the address to another instance in the case of instance failure, and to use DNS hostnames for all other inter-node communication. EIPs are specific to a region, i.e an elastic IP from one region cannot be assigned to an instance within a VPC in another region There is a one to one relationship between network interfaces and Elastic IPs. You can move elastic IPs between instances either in the same VPC or a different VPC within the same region. EIPs remain associated with your account until you explicitly release them There are charges associated with EIPs allocated to your account event when they are not associated with a resource. Elastic network interfaces (ENIs) - Virtual network interfaces that you can attach to an instance in a VPC. ENIs are only available within a VPC and are associated th a subnet upon creation ENIs can have one public address and multiple private addresses. If there are multiple private addresses, one of them is primary. Assigning a second network interface to an instance via an ENI allows the instance to be dual homed, i.e present in two subnets An ENI created independently of a particular instance persists regardless of the lifetime of any instance to which it is attached i.e if an underlying instance fails, the IP address may be preserved by attaching the ENI to a replacement instance ENIs allow you to - Create a management network Use network and security appliances in your VPC Create dual homed instances with workloads/roles on distinct subnets create a low budget, high availability solution Virtual Private gateway - You can optionally connect your VPC to your own corporate data center using an IPsec AWS managed VPN connection, making the AWS Cloud an extension of your data center. A VPN connection consists of a virtual private gateway attached to your VPC and a customer gateway located in your data center. A virtual private gateway is the VPN concentrator on the Amazon side of the VPN connection. A customer gateway is a physical device or software appliance on your side of the VPN connection. There is currently no support for IPv6 traffic. (also see picture 1) Any traffic from your private subnet going to an Elastic IP address for an instance in the public subnet goes over the Internet, and not over the virtual private gateway. You could instead set up a route and security group rules that enable the traffic to come from your private subnet over the virtual private gateway to the public subnet. The VPN connection is configured either as a statically-routed VPN connection or as a dynamically-routed VPN connection (using BGP). If you select static routing, you'll be prompted to manually enter the IP prefix for your network when you create the VPN connection. If you select dynamic routing, the IP prefix is advertised automatically to the virtual private gateway for your VPC using BGP. Amazon VPC supports multiple customer gateways, each having a VPN connection to a single VPG (many to one design). To support this topology, the customer gateway IPs must be unique within the region. The VPN connection consists of two IPSec tunnels for high availability to the Amazon VPC The connection must be initiated from the customer gateway (CGW) to the VPG (Amazon side) VPC Peering - A VPC peering connection is a networking connection between two VPCs that enables you to route traffic between them using private IPv4 addresses or IPv6 addresses. Instances in either VPC can communicate with each other as if they are within the same network. You can create a VPC peering connection between your own VPCs, or with a VPC in another AWS account. The VPCs can be in different regions (also known as an inter-region VPC peering connection). AWS uses the existing infrastructure of a VPC to create a VPC peering connection; it is neither a gateway nor a VPN connection, and does not rely on a separate piece of physical hardware. There is no single point of failure for communication or a bandwidth bottleneck. Always peered in a start/hub-spoke topology and can never be transitive. If you want all VPCs to communicate with each other then they have to be in full mesh If either VPC in a peering relationship has one of the following connections, you cannot extend the peering relationship to that connection: A VPN connection or an AWS Direct Connect connection to a corporate network An internet connection through an internet gateway An internet connection in a private subnet through a NAT device A VPC endpoint to an AWS service; for example, an endpoint to Amazon S3. (IPv6) A ClassicLink connection. You can enable IPv4 communication between a linked EC2-Classic instance and instances in a VPC on the other side of a VPC peering connection. However, IPv6 is not supported in EC2-Classic, so you cannot extend this connection for IPv6 communication. Your VPC automatically comes with a main route table that you can modify. You can also connect a peering connection between a subnet in one VPC with a subnet in another VPC, instead of peering the entire VPCs Also see pic 3 below A VPC may come with multiple peering connections, however the peerings are always 1-1, which means that two VPCs can only have one peering connection between them. VPC peering process - To establish a VPC peering connection, you do the following: The owner of the requester VPC sends a request to the owner of the accepter VPC to create the VPC peering connection. The accepter VPC can be owned by you, or another AWS account, and cannot have a CIDR block that overlaps or matches with the requester VPC's CIDR block (CIDR 10.0.0.0/24 and 10.0.0.0/16 cannot be peered as they overlap). If the accepter VPC is in the same account as the requester, it is identified by the VPC ID. If it is in a different account, it is identified by the VPC ID and Account ID. The owner of the accepter VPC accepts the VPC peering connection request to activate the VPC peering connection. Note that the owner has one week to accept or reject the response, else the peering request will expire. To enable the flow of traffic between the VPCs using private IP addresses, the owner of each VPC in the VPC peering connection must manually add a route to one or more of their VPC route tables that points to the IP address range of the other VPC (the peer VPC). If required, update the security group rules that are associated with your instance to ensure that traffic to and from the peer VPC is not restricted. If both VPCs are in the same region, you can reference a security group from the peer VPC as a source or destination for ingress or egress rules in your security group rules. By default, if instances on either side of a VPC peering connection address each other using a public DNS hostname, the hostname resolves to the instance's public IP address. To change this behavior, enable DNS hostname resolution for your VPC connection. After enabling DNS hostname resolution, if instances on either side of the VPC peering connection address each other using a public DNS hostname, the hostname resolves to the private IP address of the instance. AWS Private link - AWS PrivateLink is a highly available, scalable technology that enables you to privately connect your VPC to supported AWS services, services hosted by other AWS accounts (VPC endpoint services), and supported AWS Marketplace partner services. You do not require an internet gateway, NAT device, public IP address, AWS Direct Connect connection, or VPN connection to communicate with the service. Traffic between your VPC and the service does not leave the Amazon network. Security group important points - You may change the rules in the default security group, but you cannot delete the default security group You can create upto 10000 security groups for each VPC Maximum inbound or outbound rules per SG - 60. If you need more rules than this, you can add upto 16 security groups with each network interface You can only create allow rules (whitelist traffic) and cannot create deny rules You can create separate rules for inbound and outbound traffic Default rule in any new security group is allow all outbound and deny all inbound Instances within the same security group cannot talk to each other unless you add rules to allow this (except for the default security group) Changing a security group associated with an instance will take effect immediately. Network ACL important points - Amazon VPCs are created with a modifiable default NACL that is associated with every subnet, that allows all inbound and outbound traffic. When you create a custom NACL, it will deny all outbound and outbound traffic until you create rules to allow specific traffic. Every subnet must be associated with a NACL. NACLs are a backup layer of security which are used in addition to security groups Security groups vs NACLs - Network ACL Operates at the subnet level. You can have one subnet associated with only one NACL while an NACL can contain multiple subnets. If you associate a subnet with a new NACL, previous association is removed. Supports allow rules and deny rules Is stateless: Return traffic must be explicitly allowed by rules NACLs process rules in number order when deciding whether to allow traffic Automatically applies to all instances in the subnets it's associated with (therefore, you don't have to rely on users to specify the security group) Can only be associated with one VPC - cannot span VPCs NACLs are assessed before security groups Your VPC automatically comes with a deafult NACL which be default allows all incoming and outgoing traffic. Each subnet in your VPC must be associated with at least one NACL. If this is not done, the subnet is automatically associated with the default NACL. NACLs span AZs, but subnets don't. 1subnet = 1 AZ Security Group Operates at instance level Supports allow rules only Is stateful: Return traffic is automatically allowed, regardless of any rules We evaluate all rules before deciding whether to allow traffic Applies to an instance only if someone specifies the security group when launching the instance, or associates the security group with the instance later on Amazon security groups and network ACLs don't filter traffic to or from link-local addresses (169.254.0.0/16) or AWS-reserved IPv4 addresses—these are the first four IPv4 addresses of the subnet (including the Amazon DNS server address for the VPC). Similarly, flow logs do not capture IP traffic to or from these addresses. These addresses support the services: Domain Name Services (DNS), Dynamic Host Configuration Protocol (DHCP), Amazon EC2 instance metadata, Key Management Server (KMS—license management for Windows instances), and routing in the subnet. You can implement additional firewall solutions in your instances to block network communication with link-local addresses NAT instances - NAT instances are created in the public subnet and help the instances in the private subnet of your VPC to get access to the internet (outbound access is allowed, inbound is not allowed). These are Amazon Linux AMIs. Each NAT instance does source and destination checks by default and blocks traffic if the the NAT instance itself is not the source or destination of the traffic it sends/receives. In order for it to allow traffic to transit through it, "source-dest check" attribute must be disabled (can be done while the NAT instance is running/stopped). Amount of traffic supported by the NAT instance depends upon the instance size. If you see bottlenecks, increase the instance size. NAT instances are always behind a security group and will have an elastic/public IP. You can create high availability for NAT instances using - Auto scaling groups multiple subnets in different AZs scripting to do automatic failover NAT gateways - Preferred option for enterprises over NAT instances. It is placed in the public subnet and has the same role as the NAT instance - there should be a route out from the private subnet pointing to the NAT gateway for internet traffic to go out. A NAT gateway supports 5 Gbps of bandwidth and automatically scales up to 45 Gbps. If you require more, you can distribute the workload by splitting your resources into multiple subnets, and creating a NAT gateway in each subnet. No requirement for patching and antivirus updates - AWS manages this Not associated with any security groups Are automatically assigned a public IP NAT gateways are highly available within an AZ Don't require source/destination checks Much more secure than NAT instances You can associate exactly one Elastic IP address with a NAT gateway. You cannot disassociate an Elastic IP address from a NAT gateway after it's created. To use a different Elastic IP address for your NAT gateway, you must create a new NAT gateway with the required address, update your route tables, and then delete the existing NAT gateway if it's no longer required. You cannot associate a security group with a NAT gateway. You can use security groups for your instances in the private subnets to control the traffic to and from those instances. A NAT gateway can be created in a public or private subnet (both options are there). However, if you need it to provide access to internet for private subnets, it must be added in the public subnet and have a public IP NAT gateway CANNOT be created without an elastic IP To create an AZ independent architecture, create a NAT gateway in each AZ and configure your routing to ensure that resources use the NAT gateway in the same AZ. If you no longer need a NAT gateway, you can delete it. Deleting a NAT gateway disassociates its Elastic IP address, but does not release the address from your account. To troubleshoot instances that can’t connect to the Internet from a private subnet using a NAT gateway, check the following: Verify that the destination is reachable by pinging the destination from another source using a public IP address. Verify that the NAT gateway is in the Available state. If the NAT gateway is in the Failed state, follow the troubleshooting steps at NAT Gateway Goes to a Status of Failed. Note: A NAT gateway in the Failed state is automatically deleted after about an hour. Make sure that you've created your NAT gateway in a public subnet, and that that the public route table has a default route pointing to an Internet gateway. Make sure that the private subnet’s route table has a default route pointing to the NAT gateway. Note: Ensure that you’re not using the same route table for both the private and the public subnet; this will not route traffic to the Internet. Check that you have allowed the required protocols and ports for outbound traffic to the Internet. Make sure you've allowed access to the Internet on the security group and network ACLs associated with your VPC, and that you don’t have any rules that block traffic. For example, if you’re connecting to a server, consider allowing traffic on HTTP port 80 and HTTPS port 443, using the destination IP address 0.0.0.0/0. For more information, see Amazon EC2 Security Groups for Linux Instances or Amazon EC2 Security Groups for Windows Instances; for more information on configuring network ACLs, see Working with Network ACLs. Elastic Load Balancers - A load balancer accepts incoming traffic from clients and routes requests to its registered targets (such as EC2 instances) in one or more Availability Zones. The load balancer also monitors the health of its registered targets and ensures that it routes traffic only to healthy targets. When the load balancer detects an unhealthy target, it stops routing traffic to that target, and then resumes routing traffic to that target when it detects that the target is healthy again. Three types of load balancers - Application Load Balancer For http/https traffic load balancing operates at request level used for microservices and containers you need at least two public subnets (i.e two AZs) to deploy application load balancing Network Load Balancer operates at connection level you nee to use static IP addresses can handle millions of connections per second while maintaining ultra low latency Classic load balancer (being phased out) VPC Flow logs - Enables you to capture information about the IP traffic going in/out of your network interfaces in the VPC Flow data is stored using Amazon cloud watch logs Can also be stored in an S3 bucket Can be created at 3 levels - VPC Subnet Network interface Flow logs cannot be tagged Can be streamed to AWS Lambda for proactive monitoring. Can also be streamed to Amazon elastic search service Flow logs cannot be enabled to VPCs peered to other VPCs unless the peer VPC is in your account Flow log configuration cannot be changed after it is created. e.g you cannot associate a different IAM role with a flow log after creation Types of traffic NOT monitored by flow logs (similarity with NACLs and Security groups)- Traffic generated by instances when they contact the Amazon DNS server If you use your own DNS server, this traffic CAN BE LOGGED Traffic generated by windows instances for Amazon Windows licence activation Traffic to and from 169.254.169.254 instance metadata DHCP traffic Traffic from reserved IP addresses for default VPC routes Bastion Server - Type of jump server to SSH/RDP into instances in a private subnet (usually used for administration of such instances). They are different from NAT instances and gateways as the NAT instances/gateways are used to provide internet access to instances in private subnets. Deleting a default VPC does not delete the key pairs VPC end points - A VPC endpoint enables you to privately connect your VPC to supported AWS services and VPC endpoint services powered by PrivateLink without requiring an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection. Instances in your VPC do not require public IP addresses to communicate with resources in the service. Traffic between your VPC and the other service does not leave the Amazon network. Endpoints are virtual devices. They are horizontally scaled, redundant, and highly available VPC components that allow communication between instances in your VPC and services without imposing availability risks or bandwidth constraints on your network traffic. By default, IAM users do not have permission to work with endpoints. You can create an IAM user policy that grants users the permissions to create, modify, describe, and delete endpoints. Two types of VPC end points - Interface end points (Powered by AWS PowerLink) - An interface endpoint is an elastic network interface with a private IP address that serves as an entry point for traffic destined to a supported service. Gateway Endpoint - A gateway endpoint is a gateway that is a target for a specified route in your route table, used for traffic destined to a supported AWS service. The following AWS services are supported: Amazon S3 DynamoDB Additional notes on VPC endpoints - VPC endpoints are supported within the same region only. You cannot create an endpoint between a VPC and a service in another region. VPC endpoint always takes precedence over a NAT or an internet gateway. In case a VPC endpoint is missing, requests to the AWS service are routed to an internet gateway or a NAT gateway (depending upon the route in the routing table) When you create a gateway endpoint, you can attach an endpoint policy to it that controls access to the service to which you are connecting. Endpoint policies must be written in JSON format. A VPC endpoint policy is an IAM resource policy that you attach to an endpoint when you create or modify the endpoint. If you do not attach a policy when you create an endpoint, Amazon attach a default policy for you that allows full access to the service. An endpoint policy does not override or replace IAM user policies or service-specific policies (such as S3 bucket policies). It is a separate policy for controlling access from the endpoint to the specified service. You can create multiple endpoints to a single AWS service and can enforce different route tables to enforce different access policies from different subnets to the same service. Process to create an endpoint - Specify the amazon VPC Specify the service - com.amazonaws.. Specify the policy. You can allow full access or create a custom policy. This policy can be changed at any time Specify the route tables. A route will be added to each specified table which will state the service as the destination and the endpoint as the target. See pic below on route table for an endpoint that is set as target for a destination S3 bucket You cannot create VPC peering connection between two VPCs with matching or overlapping IP addresses/CIDRs (eg. if both are in the range 10.0.0.0/8, you cannot peer them) If you create a NAT gateway and it goes to a status of Failed, there was an error when it was created. A failed NAT gateway is automatically deleted after a short period; usually about an hour. By default, IAM users do not have permission to work with NAT gateways. You can create an IAM user policy that grants users permissions to create, describe, and delete NAT gateways. We currently do not support resource-level permissions for any of the ec2:*NatGateway* API operations. S3 proxy question in wizlabs Secondary CIDR - Amazon Virtual Private Cloud (VPC) now allows customers to expand their VPCs by adding secondary IPv4 address ranges (CIDRs) to their VPCs. Customers can add the secondary CIDR blocks to the VPC directly from the console or by using the CLI after they have created the VPC with the primary CIDR block. Similar to the primary CIDR block, secondary CIDR blocks are also supported by all the AWS services including Elastic Load Balancing and NAT Gateway. This feature has two key benefits. Customers, who are launching more and more resources in their VPCs, can now scale up their VPCs on-demand. Customers no longer have to over-allocate private IPv4 space to their VPCs - they can allocate only what is required at the time, and later expand it as needed. Note that the primary CIDR can never be deleted. Secondary CIDR can be deleted any time. Make sure you create the VPC infrastructure from scratch before the exam Read VPC FAQs
{kind=link}
{kind=link}
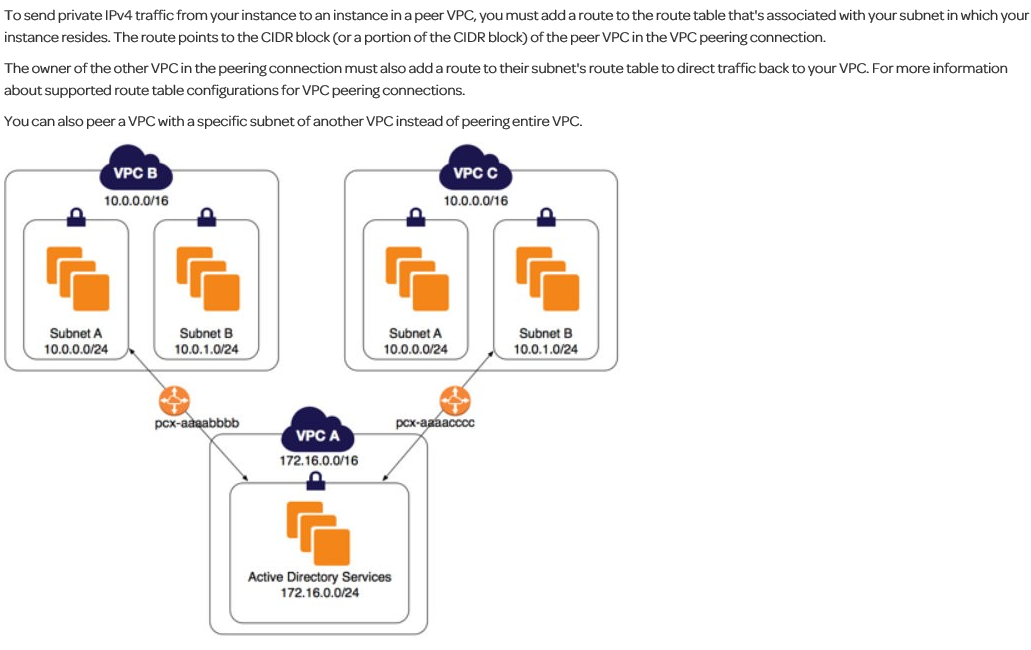{kind=link}
{kind=link}
Page 8
Amazon Elastic Load Balancing (ELB)
With AWS, you can use your own virtual load balancer on EC2 instances or use Amazon's managed load balancer service call Amazon Elastic Load balancer Elastic Load balancer - Allows you to distribute traffic across a group of EC2 instances available in one to more AZs Supports routing and load balancing of http, https, TCP and SSL traffic to EC2 instances Load balancers can be both - internet facing and internal application facing Provides a simple, stable CNAME entry point for DNS Supports health checks for EC2 instances to ensure traffic is not routed to an unhealthy instance. It can also scale automatically based on collected metrics and to meet demands of increased application traffic Helps achieve high availability for your applications by distributing traffic across healthy instances in different AZs (in the same region) It seamlessly integrates with the Autoscaling service to automatically scale EC2 instances behind the load balancer. Is secure with VPC to route traffic between application Tiers allowing you to expose only the internet facing public IP. It supports integrated certification management and SSL termination When you configure a load balancer, it receives a public DNS name that clients can use to send their requests to. AWS recommends that the ELB should always be referenced by the DNS name rather than the public IP. Listeners - Every ELB must have one or more listeners configured. A listener is a process that checks for connection requests (e.g CNAME configured to the A record of the load balancer). Every listener is configured with a protocol and port # (client to LB) for front end connection and protocol and port # (LB to EC2) for back end connection. ELB supports the following protocols (layer 4 and layer 7 of the OSI layer)- HTTP - Layer 7 HTTPS - Layer 7 TCP - Layer 4 SSL - Layer 4 Three types of load balancers - Application Load Balancers - Best suited for load balancing of http and https traffic, when you need flexible application management and TLS termination Operate at layer 7 and are application aware They are intelligent and you can create advanced request routing, sending specific requests to specific web serves You can perform load balancing for the following TCP ports: 1-65535 These are of three types - Internet Facing Load Balancers - take requests from clients over the internet and distribute them to Amazon EC2 instances that are registered with the load balancer Internal load balancers - Used to route traffic to EC2 instances within private subnets of your VPCs HTTPS Load balancers - Uses SSLTLS protocol for encrypted connections (also known as SSL offload). This feature enables traffic encryption between your load balancer and clients that are initiating the https connection, and for connections between your load balancer and back end instances. In order to use SSL, you must install an SSL certificate on your load balancer that the load balancer will use to decrypt traffic from your client before sending them to the back end instances. Network Load Balancers - Best suited for load balancing of TCP traffic where extreme performance is required Operate at layer 4 Capable of handling millions of requests per second while maintaining ultra low latency Also used when you need a static IP Network Load Balancer provides TCP (Layer 4) load balancing. It is architected to handle millions of requests/sec, sudden volatile traffic patterns and provides extremely low latencies. In addition Network Load Balancer also preserves the source IP of the clients, provides stable IP support and Zonal isolation. It also supports long-running connections that are very useful for WebSocket type applications. Network Load balancers are also of two types - Internet facing and Internal Classic Load balancers (if the exam mentions just ELB, it means classic load balancer) Legacy load balancer for classic EC2 instances Used for load balancing http and https traffic and can use layer7 features such as X-forwarded and sticky sessions You can also use strict layer 4 load balancing for applications that rely purely on TCP protocol Load balancer error 504 - Load balancer responds with this error if your application stops responding. Possible causes can be - application is having issues at the web server layer or database layer To troubleshoot this, check where the application is failing and scale in or scale out where possible Configuring ELBs (parameters that you can configure) Idle connection timeout - For each request made by the client, ELB maintains two connections - client to ELB and ELB to internal instances. For each connection there is an idle timeout that is triggered when no data is sent over the connection for a specified time period. After the idle timeout is elapsed, no data is sent or received an the ELB closes the connection. Default idle timeout is 60 secs for both connections. You can increase this time for lengthy operations such as file uploads. If you use http and https listeners then it is recommended to set a keepalive timer. This timer allows the load balancer to reuse the connections to your back end instances and educe CPU utilization. Cross zone load balancing - Enables load balancing to instances regardless of the AZ where they are located. For environments where clients cache DNS lookups, incoming requests may favour a particular AZ. Cross zone load balancing prevents this imbalance Connection draining - This is enabled to ensure that the load balancer will stop sending equests to instances that are deregistering or unhealthy, while keeping existing connections open. This helps load balancers to complete in-flight requests made to these instances. You can specify the maximum amount of time for load balancers to keep connections alive before reporting the instance as deregistered. The maximum timeout can be set between 1 to 3600 seconds (default 300 seconds). When maximum time limit is reached the load balancer forcibly closes the connection to the deregistering service. Proxy protocol - This is used if you need the IP address/public IP of the end user. When you use TCP/SSL front and backend connections, your load balancer forwards requests to back end instances without modifying the request header. With proxy protocol, the load balancer adds a human readable header called X-header that contains information about the source and destination IPs and port numbers of the requesting client. This header is sent to the back end instance as part of the request. Sticky sessions - Enables the load balancer to bind a user session to a specific instance. This can be done in 2 ways - If your application has a session cookie, you can configure the ELB so that the session cookie follows the duration specified by the application's session cookie If your application does not have a session cookie, you can configure the ELB to create a cookie by specifying your own session stickiness duration. The cookie that ELB creates is called AWSELB Health Checks - ELB supports health checks to test the status of instances. The health check can be a simple ping, a connection attempt or a page that is checked periodically. You can set time between health checks and a threshold for number of consecutive health check failures before the instance is marked unhealthy. There are two statuses or health checks of EC2 instances - InService - The instance is healthy at the time of the health check OutOfService - The instance is unhealthy at the time of health check If a target is taking longer than expected to enter the InService state, it might be failing health checks. Your target is not in service until it passes one health check. Verify that your instance is failing health checks and then check for the following: A security group does not allow traffic A network access control list (ACL) does not allow traffic The ping path does not exist The connection times out The target did not return a successful response code (default success code is 200) Ways to monitor your application load balancers - CloudWatch metrics Access logs Request tracing CloudTrail logs Target types for ELBs- When you create a target group, you specify its target type, which determines the type of target you specify when registering targets with this target group. After you create a target group, you cannot change its target type. The following are the possible target types: Instance ID IP address (This has to be a private IP. You cannot specify publicly routable IP addresses) Target Lambda function FAQs Q: Can I privately access Elastic Load Balancing APIs from my Amazon Virtual Private Cloud (VPC) without using public IPs? A: Yes, you can privately access Elastic Load Balancing APIs from your Amazon Virtual Private Cloud (VPC) by creating VPC endpoints. With VPC endpoints, the routing between the VPC and Elastic Load Balancing APIs is handled by the AWS network without the need for an Internet gateway, NAT gateway, or VPN connection. The latest generation of VPC Endpoints used by Elastic Load Balancing are powered by AWS PrivateLink, an AWS technology enabling the private connectivity between AWS services using Elastic Network Interfaces (ENI) with private IPs in your VPCs. Q: Can I configure a security group for the front-end of an Application Load Balancer? A: Yes. Q: Can I convert my Classic Load Balancer to an Application Load Balancer (and vice versa)? A: No, you cannot convert one load balancer type into another. Q: Can I migrate to Application Load Balancer from Classic Load Balancer? A: Yes. You can migrate to Application Load Balancer from Classic Load Balancer Q: Can I use an Application Load Balancer as a Layer-4 load balancer? A: No. If you need Layer-4 features, you should use Network Load Balancer. Q: Can I use a single Application Load Balancer for handling HTTP and HTTPS requests? A: Yes, you can add listeners for HTTP port 80 and HTTPS port 443 to a single Application Load Balancer. Q: Can I get a history of Application Load Balancing API calls made on my account for security analysis and operational troubleshooting purposes? A: Yes. To receive a history of Application Load Balancing API calls made on your account, use AWS CloudTrail. Q: Does an Application Load Balancer support HTTPS termination? A: Yes, you can terminate HTTPS connection on the Application Load Balancer. You must install an SSL certificate on your load balancer. The load balancer uses this certificate to terminate the connection and then decrypt requests from clients before sending them to targets. Q. How can I protect my web applications behind a load balancer from web attacks? A: You can integrate your Application Load Balancer with AWS WAF, a web application firewall that helps protect web applications from attacks by allowing you to configure rules based on IP addresses, HTTP headers, and custom URI strings. Using these rules, AWS WAF can block, allow, or monitor (count) web requests for your web application. Q: How can I load balance applications distributed across a VPC and on-premises location? A: There are various ways to achieve hybrid load balancing. If an application runs on targets distributed between a VPC and an on-premises location, you can add them to the same target group using their IP addresses. To migrate to AWS without impacting your application, gradually add VPC targets to the target group and remove on-premises targets from the target group. If you have two different applications such that the targets for one application are in a VPC and the targets for other applications are in on-premises location, you can put the VPC targets in one target group and the on-premises targets in another target group and use content based routing to route traffic to each target group. You can also use separate load balancers for VPC and on-premises targets and use DNS weighting to achieve weighted load balancing between VPC and on-premises targets. Q: How do I enable cross-zone load balancing in Application Load Balancer? A: Cross-zone load balancing is already enabled by default in Application Load Balancer. Q: How does Lambda invocation via Application Load Balancer work? A: HTTP(S) requests received by a load balancer are processed by the content-based routing rules. If the request content matches the rule with an action to forward it to a target group with a Lambda function as a target then the corresponding Lambda function is invoked. The content of the request (including headers and body) is passed on to the Lambda function in JSON format. The response from the Lambda function should be in JSON format. The response from the Lambda function is transformed into an HTTP response and sent to the client. The load balancer invokes your Lambda function using the AWS Lambda Invoke API and requires that you have provided invoke permissions for your Lambda function to Elastic Load Balancing service. Q: How does Network Load Balancer compare to what I get with the TCP listener on a Classic Load Balancer? A: Network Load Balancer preserves the source IP of the client which in the Classic Load Balancer is not preserved. Customers can use proxy protocol with Classic Load Balancer to get the source IP. Network Load Balancer automatically provides a static IP per Availability Zone to the load balancer and also enables assigning an Elastic IP to the load balancer per Availability Zone. This is not supported with Classic Load Balancer. Classic Load Balancer provides SSL termination that is not available with Network Load Balancer. Q: Can I migrate to Network Load Balancer from Classic Load Balancer? A: Yes. You can migrate to Network Load Balancer from Classic Load Balancer using one of the options listed in this document. Q: Can I have a Network Load Balancer with a mix of ELB-provided IPs and Elastic IPs or assigned private IPs? A: No. A Network Load Balancer’s addresses must be completely controlled by you, or completely controlled by ELB. This is to ensure that when using Elastic IPs with a Network Load Balancer, all addresses known to your clients do not change. Q: Can I assign more than one EIP to my Network Load Balancer in each subnet? A: No. For each associated subnet that a Network Load Balancer is in, the Network Load Balancer can only support a single public/internet facing IP address. Q: If I remove/delete a Network Load Balancer what will happen to the Elastic IP addresses that were associated with it? A: The Elastic IP Addresses that were associated with your load balancer will be returned to your allocated pool and made available for future use.
Page 9
Autoscaling
With autoscaling, you can ensure that the number of EC2 instances increases during peak demand and automatically decreases during troughs to maintain performance and controlling costs Auto scaling plans - Maintain current instance levels Autoscaling group will maintain a minimum number of instances at all times Autoscaling performs a periodic health check on running instances within the autoscaling group. When Auto scaling finds an unhealthy instance it terminates that instance and launches a new one Best for steady workloads Manual scaling Manual scaling is the most basic way to scale your resources Specify only the change in the maximum, minimum, or desired capacity of your Auto Scaling group. Amazon EC2 Auto Scaling manages the process of creating or terminating instances to maintain the updated capacity Useful to increase resources for an infrequent event such as a new game that will be available for download and will require user registration Scheduled scaling Sometimes you know exactly when you will need to increase or decrease the number of instances in your group, simply because that need arises on a predictable schedule. Scaling by schedule means that scaling actions are performed automatically as a function of time and date. Examples include periodic events such as end of month, end of quarter, end of year processing or other predictable reccuring events. Dynamic Scaling A more advanced way to scale your resources, scaling by policy, lets you define parameters that control the scaling process For example, you can create a policy that calls for enlarging your fleet of EC2 instances whenever the average CPU utilization rate stays above ninety percent for fifteen minutes. This is useful for scaling in response to changing conditions, when you don't know when those conditions will change. You can set up Amazon EC2 Auto Scaling to respond for you. Auto scaling configuration Launch configuration - Template that auto scaling uses to create new instances. Default limit for launch configuration is 100 per region. If you exceed this limit, the call to create-launch-configuration will fail. You may view and update this limit by running the command - >aws autoscaling describe-account-limits. Launch configuration template will include the following and will be created with the command >aws autoscaling create-launch-configuration ...<> Configuration name AMI type Instance type Security group (Optional) Instance key pair (Optional) Block device mapping (Optional) Auto scaling group - Is a collection of EC2 instances managed by the autoscaling service Contains configuration options that specify when the autoscaling group should launch new instances or terminate existing ones Group configuration will include Group name Launch Configuration AZ Minimum number of instances Desired number of instances (if you dont specify this, it will take minimum number as desired) Maximum number of instances Load balancers Autoscaling group can either on demand or spot instances. Default is on-demand, but spot instances can be used by referencing the maximum bid price in the launch configuration. An Autoscaling group can reference either on demand or spot instances, but not both. Scaling policy - You can associate Cloudwatch alarms and scaling policies with an auto scaling group to adjust auto scaling dynamically. When a threshold is crossed, Cloudwatch sends alarms to trigger scaling in/out to the number of EC2 instances receiving traffic behind a load balancer. Ways to configure a scaling policy - Increase or decrease by a specific number of instances Target a specific number of instances Adjust based on percentage Scale by steps based on size of alarm threshold trigger You can associate more than one scaling policy with an auto scaling group. A recommended best practice is to scale out quickly and scale in slowly, so you can respond to bursts and spikes, but avoid inadvertently terminating EC2 instances too quickly, only having to launch more EC2 instances if the burst is sustained. Auto scaling also supports a cool down period which is a configurable setting that determines when to suspend scaling activities for a short time for an auto scaling group If you start an EC2 instance, you are billed for full hours even if you have used them for a partial hour It is important to consider bootstrapping for EC2 instances launched using auto scaling Suspending and resuming scaling - You can suspend and then resume one or more of the scaling processes for your Auto Scaling group. This can be useful for investigating a configuration problem or other issues with your web application and making changes to your application without invoking the scaling processes Amazon EC2 Auto Scaling can suspend processes for Auto Scaling groups that repeatedly fail to launch instances. This is known as an administrative suspension. It most commonly applies to Auto Scaling groups that have been trying to launch instances for over 24 hours but have not succeeded in launching any instances. You can resume processes suspended for administrative reasons. Amazon EC2 Auto Scaling supports the following scaling processes that can be suspended and resumed - Launch - Adds a new EC2 instance to the group, increasing its capacity. If you suspend Launch, this disrupts other processes. For example, you can't return an instance in a standby state to service if the Launch process is suspended, because the group can't scale. Terminate - Removes an EC2 instance from the group, decreasing its capacity. If you suspend Terminate, it disrupts other processes. Healthcheck - Checks the health of the instances. Amazon EC2 Auto Scaling marks an instance as unhealthy if Amazon EC2 or Elastic Load Balancing tells Amazon EC2 Auto Scaling that the instance is unhealthy. This process can override the health status of an instance that you set manually. Replaceunhealthy - Terminates instances that are marked as unhealthy and later creates new instances to replace them. This process works with the HealthCheck process, and uses both the Terminate and Launch processes. AZRebalance - Balances the number of EC2 instances in the group across the Availability Zones in the region. If you remove an Availability Zone from your Auto Scaling group or an Availability Zone otherwise becomes unhealthy or unavailable, the scaling process launches new instances in an unaffected Availability Zone before terminating the unhealthy or unavailable instances. When the unhealthy Availability Zone returns to a healthy state, the scaling process automatically redistributes the instances evenly across the Availability Zones for the group. If you suspend AZRebalance and a scale-out or scale-in event occurs, the scaling process still tries to balance the Availability Zones. For example, during scale out, it launches the instance in the Availability Zone with the fewest instances. If you suspend the Launch process, AZRebalance neither launches new instances nor terminates existing instances. This is because AZRebalance terminates instances only after launching the replacement instances. If you suspend the Terminate process, your Auto Scaling group can grow up to ten percent larger than its maximum size, because this is allowed temporarily during rebalancing activities. If the scaling process cannot terminate instances, your Auto Scaling group could remain above its maximum size until you resume the Terminate process. Alarm notification - Accepts notifications from CloudWatch alarms that are associated with the group. If you suspend AlarmNotification, Amazon EC2 Auto Scaling does not automatically execute policies that would be triggered by an alarm. If you suspend Launch or Terminate, it is not able to execute scale-out or scale-in policies, respectively. ScheduledAction- Performs scheduled actions that you create. If you suspend Launch or Terminate, scheduled actions that involve launching or terminating instances are affected. AddtoLoadbalancer - Adds instances to the attached load balancer or target group when they are launched. If you suspend AddToLoadBalancer, Amazon EC2 Auto Scaling launches the instances but does not add them to the load balancer or target group. If you resume the AddToLoadBalancer process, it resumes adding instances to the load balancer or target group when they are launched. However, it does not add the instances that were launched while this process was suspended. You must register those instances manually. Default Termination Policy - The default termination policy is designed to help ensure that your instances span Availability Zones evenly for high availability. With the default termination policy, the behavior of the Auto Scaling group is as follows: Determine which Availability Zone(s) have the most instances and at least one instance that is not protected from scale in. If there are multiple unprotected instances to choose from in the Availability Zone(s) with the most instances: For Auto Scaling groups configured to launch instances across pricing options and instance types: Determine which instance to terminate so as to align the remaining instances to the allocation strategies for On-Demand and Spot Instances, your current selection of instance types, and distribution across your N lowest priced Spot pools. If there are multiple instances to choose from, determine whether any of these instances use the oldest launch configuration or template. If there is one such instance, terminate it. For Auto Scaling groups that use a launch configuration: Determine whether any of these instances use the oldest launch configuration. If there is one such instance, terminate it. If there are multiple unprotected instances to terminate based on the above criteria, determine which instances are closest to the next billing hour. (This helps you maximize the use of your instances that have an hourly charge.) If there is one such instance, terminate it. If there are multiple unprotected instances closest to the next billing hour, choose one of these instances at random. Lifecycle hooks: You can add a lifecycle hook to your Auto Scaling group so that you can perform custom actions when instances launch or terminate .When Amazon EC2 Auto Scaling responds to a scale out event, it launches one or more instances. These instances start in the Pending state. If you added an autoscaling:EC2_INSTANCE_LAUNCHING lifecycle hook to your Auto Scaling group, the instances move from the Pending state to the Pending:Wait state. The instance is paused until either you continue or the timeout period ends. After you complete the lifecycle action, the instances enter the Pending:Proceed state. When the instances are fully configured, they are attached to the Auto Scaling group and they enter the InService state. When Amazon EC2 Auto Scaling responds to a scale in event, it terminates one or more instances. These instances are detached from the Auto Scaling group and enter the Terminating state. If you added an autoscaling:EC2_INSTANCE_TERMINATING lifecycle hook to your Auto Scaling group, the instances move from the Terminating state to the Terminating:Wait state. After you complete the lifecycle action, the instances enter the Terminating:Proceed state. When the instances are fully terminated, they enter the Terminated state. Cooldown period - When an Auto Scaling group launches or terminates an instance due to a simple scaling policy, a cooldown takes effect. The cooldown period helps ensure that the Auto Scaling group does not launch or terminate more instances than needed. When the instance enters the wait state, scaling actions due to simple scaling policies are suspended. When the instance enter the InService state, the cooldown period starts. When the cooldown period expires, any suspended scaling actions resume. If you configure your Auto Scaling group to determine health status using both EC2 status checks and Elastic Load Balancing health checks, it considers the instance unhealthy if it fails either the status checks or the health check. If you attach multiple load balancers to an Auto Scaling group, all of them must report that the instance is healthy in order for it to consider the instance healthy. If one load balancer reports an instance as unhealthy, the Auto Scaling group replaces the instance, even if other load balancers report it as healthy. Health check grace period - Frequently, an Auto Scaling instance that has just come into service needs to warm up before it can pass the health check. Amazon EC2 Auto Scaling waits until the health check grace period ends before checking the health status of the instance. Amazon EC2 status checks and Elastic Load Balancing health checks can complete before the health check grace period expires. However, Amazon EC2 Auto Scaling does not act on them until the health check grace period expires. To provide ample warm-up time for your instances, ensure that the health check grace period covers the expected startup time for your application. If you add a lifecycle hook, the grace period does not start until the lifecycle hook actions are completed and the instance enters the InService state.
Page 10
Databases and AWS
Relational database types (in AWS they are the RDS/OLTP types)- Structure of the table such as the number of columns and the data type of the column should be defined prior to adding data to the table. The structure cannot be changed later. Oracle Microsoft SQL server MySQL PosgreSQL Amazon Aurora (supports both MySQL and PostgreSQL) MariaDB Components of non relational databases (in AWS, this is DynamoDB) - Collection (=Table) Documents (=Rows) Key-value pairs (=Fields) Use cases for non relational/NoSQL databases - managing user session state user profiles hopping cart data time series data Amazon Elasticache - Web service that makes it easy to deploy, operate and scale in memory cache in the cloud. The service improves the performance of web applications by allowing you to retrieve information from fast, managed, in-memory caches instead of relying entirely on slow disk based databases. It supports two open source in-memory caching engines - Redis Memcache Many organizations split their Relational databases into categories - Online transaction processing (OLTP) databases - For Transaction oriented applications that are frequently writing and changing data (eg. data entry and e-commerce - you search for an order no. and it will return all details related to an order including date of order, delivery address, delivery status etc.). This is usually the main production database for OLTP transactions Online analytical processing (OLAP) database - Used for data warehousing and refers to reporting or analyzing large data sets (eg, if you need to calculate net profit of a product in AMEA and Europe, this will need to fetch data from many databases to an offline data warehouse - OLAP where analytics and complex queries will be applied on the data to get net profit information for these regions). The queries are run infrequently and often in batches AWS Database migration service helps customers to migrate their existing databases to Amazon RDS service. It also helps in converting databases from one database engine to another. Amazon RDS It exposes a database endpoint to which a client software can connect and execute SQL. It does not provide shell access to the database instances and restricts access to certain system procedures and tables that require advanced privileges. Existing Extract, Transform and Load (ETL) workloads can connect the the DB instance in the same way with the same drivers and often all it takes to reconfigure is changing the hostname in the connection string. DB Instances - You can launch a new DB Instance by calling the CreateDBInstance API or using the AWS management console. Existing DB instances can be modified by calling the ModifyDBInstance API. A DBInstance can contain multiple different databases that you can create and manage by executing SQL commands with the Amazon RDS endpoint. These databases can be created, accessed and managed using the same SQL client tools and applications that you use today. The compute and memory resources of a DB instance are determined by its instance class. As your needs change over time, you can change the instance class and Amazon RDS will migrate your data to a larger or smaller instance class. You can also control the size and performance of your storage independently of the instance class used. You cannot use SSH to log into the host instance and install customer piece of software on the DB instance. You can use SQL administrator tools or use DBOption groups and DBParameter groups to change behaviour or feature configuration of a DB Instance. If you want full control of the operating system or require elevated permissions to run, then consider installing your database on EC2 instead of using Amazon RDS. Amazon never provide a public IPv4 address to the customer for the RDS instance. They only provide the DNS address. Database Engines - MySQL Open source Supports multi-AZ deployments for HA Supports read replicas for horizontal scaling PostgreSQL Open source Supports multi-AZ deployments for HA Supports read replicas for horizontal scaling MariaDB Open source Supports multi-AZ deployments for HA Supports read replicas for horizontal scaling Oracle Supports three different editions on Amazon RDS Standard Best performance Multi AZ Supports KMS encryption Standard One Lower performance as compared to the other editions Multi AZ Supports KMS encryption Enterprise Performance as good as standard edition Multi AZ Supports both KMS and TDE encryption Microsoft SQL Server Supports four different editions Express Worst performance out of all editions No support for multi AZ Supports KMS encryption Web Intermediate performance No support for multi AZ Supports KMS encryption Standard Intermediate performance Support for multi AZ Supports KMS encryption Enterprise Best performance Supports multi AZ Supports KMS and TDE encryption Amazon Aurora Enterprise grade commercial database technology that offers simplicity and cost effectiveness of open source database (by redesigning internal components of MySQL) Provides upto 5 times better performance than MySQL. You can use the same code, tools and applications that you use with your MySQL database, with Amazon Aurora without making changes to your web applications For Amazon Aurora, you create a DB cluster and your instances are a part of the cluster. There is a cluster volume that manages data for the instances in the cluster. This volume is a virtual database storage volume that spans multiple AZs and each AZ will have a copy of the cluster data. Aurora consists of two kinds of instances - Primary instance - Main instance that supports read and write workloads. Any data modifications are done on the primary instance and each cluster must have one primary instance Amazon Aurora replica - Secondary instance that only supports read operations. Each DB cluster can have upto 15 of these (in addition to the primary instance). The read replicas improve performance by distributing read workloads among instances. Read replicas can be located in multiple AZs to increase database availability. Licensing options provided by AWS for Oracle and Microsoft SQL License included - License is held by AWSand is included in the Amazon RDS instance price. Available for Oracle standard one edition, SQL server express, web edition and standard edition Bring your own license (BYOL) - Customers provide their own license and are responsible for tracking and managing the allocation of licenses. Available for all Oracle editions and for standard and enterprise editions in MS SQL. Storage Options for Amazon RDS Built using Amazon Elastic Block Storage which provides three options - Magnetic Storage Standard Storage Lowest Cost For applications with light IO requirements (performance is lower as compared to other storage options) General Purpose SSD Also called gp2 Better performance/faster access than magnetic storage Can burst performance to meet spikes Cheaper than Provisioned IOPS but expensive than magnetic For small to medium sized databases, but is considered to be suitable for most applications as it balances performance with cost. Provisioned IOPS For I/O intensive workloads High storage performance for applications Consistency in random access I/O throughput most expensive Backup and Recovery in Amazon RDS RPO (Recovery point objective) - Maximum period of data loss hat is acceptable in event of a failure or incident. It is measured in minutes. eg. many systems back up their transaction logs every 15 minutes to allow for minimum data loss in event of accidental deletion or hardware failure RTO (Recovery time objective) - Maximum amount of downtime that is permitted to recover from back up and to resume processing. It is measured in hours or days. For eg. for large databases, it can take hours to recover from a full back up. In case of hardware failure, you can reduce your RTO by failing over to a secondary node. Amazon RDS provides two ways for backing up a database- Automated backups - Enabled by default Backup data is stored in S3 and you get free storage space equal to the size of your database. For eg. if your database instance is 10GB, you will get 10GB of storage space for back up Amazon RDS creates a storage volume snapshot of your entire DB instance rather than just individual databases Default retention period is 1 day, but can be retained for a maximum of 35 days. Automated back ups occur daily at a configurable 30 minute back up window During the back up window, I/O may be suspended which may cause latency while reading/writing to the database. All automatic back up snapshots are deleted when you delete the DB instance. These snapshots can't be recovered. Manual DB snapshots - Initiated by the customer/user and can be done as frequently as you want Can be created through the console or CreateDBSnapshot action Unlike automated backups, the manual snapshots will be retained till the user explicitly deleted them via the console or DeleteDBSnapshot action. Deleting the DB instance will not delete the associated manual snapshots. Note: - While a snapshot is being taken (manual or automatic), I/O performance of the database will be impacted (either suspended or there will be latency). To reduce the impact of this, use multi AZ deployment where the snapshot can be taken from the standby instance in another AZ. Recovery - You cannot restore from a DB snapshot to an existing DB instance - a new DB instance needs to be created and then the snapshot needs to be restored on it. The new RDS instance will also have a new DNS endpoint which will have to be updated on client applications that will connect to the database. When you restore a snapshot, only default DB parameters and security groups are associated with the restored instance. You need to create these custom security groups or DB parameters after the restore is complete For automated back ups, Amazon RDS combines daily back ups with back ups of transaction logs so that the DB instance can be restored at any point during your retention period, typically upto the last 5 minutes High availability using multi AZ- Allows creation of database cluster across multiple AZs Let's customers meet demanding RPO and RTO targets by using synchronous replication to minimize RPO and fast failover to minimize RTO to minutes. Allows you to keep a secondary copy of the database in another AZ for DR purposes. Multiple AZ deployments are available for all types of RDS database engines. Amazon RDS kicks off a failover in the following conditions - Loss of availability of primary AZ Loss of network connectivity to primary database Compute unit failure on primary database Storage failure on primary database In case of a multi AZ deployment, you are assigned a database endpoint which is a DNS name that AWS takes responsibility of resolving to an IP. You use this DNS name to connect to your database. In case of a failure, Amazon RDS automatically fails over to the standby instance without user intervention. The DNS name remains the same, but amazon RDS service changes the CNAME to point to the standby. Failovers can be triggered manually as well. Note that multi AZ deployments are for DR only. They cannot be used as a mechanism to improve database performance. If you want to improve database performance, use techniques such as read replicas or caching technologies such as elasticache. Scaling up and out - Vertical scalability - Amazon RDS makes it easy to scale up and down your database tier to meet the demands of your application. To change the amount of memory, compute, storage etc., you can select a different DB instance class of the database. After you select a smaller or larger instance class, Amazon RDS automates the migration process to the new class. Changes can be made in the next maintenance window or immediately using the ModifyDBInstance action, but this will cause a disruption Each database instance can scale from 5GB to 6TB in provisioned storage, depending upon the storage type and database engine. Storage expansion is supported on all database engines except SQL server Horizontal scaling - Can be done in two ways - Sharding - Allows you to scale horizontally to handle more users, but needs additional logic at the application layer. The application needs a mechanism to decide how to route requests to the correct shard. There are limits to the type of queries that can be performed in this model. NoSQL databases such as DynamoDB and Cassandra support this. Read replicas - For read heavy workloads such as blogs, you can improve I/O performance by creating read replicas of the primary database instance. Read replicas are asynchronous Currently supported on MySQL, PostgreSQL, Aurora, MariaDB Must be used for scaling, NOT DR Automatic back ups must be turned on to deploy read replicas Upto 5 read replicas of the primary database are possible You can create an encrypted read replica even if the primary database instance is not encrypted Each read replica will have its own DNS endpoint You can have read replicas of read replicas (but this can increase latency) Read replicas can be deployed in multi AZ as well as multi region models. Multi region models are useful to enhance DR capabilities as well as reduce global latencies (serve read traffic from region closest to users) You can create read replicas of multi-AZ source databases Read replicas can be promoted to their own databases, however this breaks replication. Common scenarios to use read replicas - Scale beyond capacity of a single DB instance for read heavy workloads Handle read heavy traffic while source DB is unavailable (due to I/O suspension or scheduled maintenance,you can redirect read traffic to the replicas) Offload reporting and data warehousing - you can use the read replica instead of using the primary DB instance. Security - Encryption: - Once your RDS instance is encrypted, the associated storage, read replicas, snapshots (automatic and manual) are all encrypted as well. You can only enable encryption for an Amazon RDS DB instance when you create it, not after the DB instance is created. However, because you can encrypt a copy of an unencrypted DB snapshot, you can effectively add encryption to an unencrypted DB instance. That is, you can create a snapshot of your DB instance, and then create an encrypted copy of that snapshot. You can then restore a DB instance from the encrypted snapshot, and thus you have an encrypted copy of your original DB instance. IAM - Use IAM to limit what actions administrators can perform on RDS instances/databases. Network - Deploy RDS instances in private VPCs. Create a DB subnet group that predefines which subnets are available for Amazon RDS deployments. Use security groups and NACLs to restrict network access from specified IP addresses. Database level - Create users and grant them access to read and write to the database itself. Amazon Redshift Relational database designed for OLAP transactions and optimized for high performance analytics and reporting of large datasets. It gives you fast querying capabilities over structured data using standard SQL commands. Provides connectivity via ODBC and JDBC Based on industry standard PostgreSQL, so mt existing SQL client applications will work with minimum changes Provides columnar data storage, where data is organized by column rather than a series of rows. Column based systems are ideal for data warehousing and analytics, as column based data is stored sequentially on storage media. This helps in fewer I/Os and improving query performance. Provides advanced compression encoding - In case of column based data, since similar data is stored sequentially on the disk, the data stores can be compressed and provide performance optimizations. Amazon Redshift also does not require indexes or materialized views (due to columnar data stores), which helps in saving storage space as compared to traditional database systems. When loading data into an empty table, Redshift automatically samples the data and choses the appropriate compression scheme for each column. Alternatively, you can specify the compression encoding on a per column basis as part of the CREATE TABLE command. Pricing is based on - Compute node hours (1 unit per node/hour - no billing for leader node) Back up Data transfer - only within a VPC, not outside it Redshift architecture is based on the concept of clusters. There are two types of clusters - Single node cluster Consists of only one node (upto 160 GB) Multi node cluster Consists of a leader node and one or more compute nodes Client application interacts only with the leader node and compute nodes are transparent to the external applications Redshift supports different node types and each has a different mix of compute, storage, memory parameters. These 6 nodes are grouped into two categories - Dense compute - support clusters upto 326 TB using fast SSDs Dense storage - support clusters upto PB using magnetic storage There can be a maximum of 128 compute nodes in a cluster. You can increase performance by adding nodes to a cluster. Amazon Redshift spreads your table data across the compute nodes based on the distribution strategy you specify. The leader node receives queries from client applications, parses the queries, and develops query execution plans. The leader node then coordinates the parallel execution of these plans with the compute nodes and aggregates the intermediate results from these nodes. It then finally returns the results back to the client applications. Disk storage for a compute node is divided into a number of slices. No. of slices depends upon the size of the node and varies between 2 and 16. The nodes participate in parallel query execution working on data that is distributed evenly as possible on the slices. Resizing - You can resize a cluster to add storage and compute capacity. You can also change the node type of a cluster and keep the overall size the same. Whenever you resize a cluster, Redshift will create a new cluster and migrate data from the old cluster to the new one. During this operation, your database will become read only till the operation is finished. Each cluster can contain multiple databases and each database can contain multiple tables Columns can be added to a table u the ALTER TABLE command, but existing columns cannot be modified (relational database property) Data distribution style hat you select for your database has the maximum impact on query performance, storage requirements, data loading and maintenance. There are three distribution styles to choose from - Even distribution- Default option - data is distributed evenly across nodes/slices Key distribution - Rows are distributed according to values in one column. Leader node will store matching values close together to improve query performance or joins All distribution - Full copy of entire table is distributed to every node. Useful for lookup tables and large tables that are not updated frequently COPY command - Loads data into a table from data files or from an Amazon DynamoDB table. The files can be located in an Amazon Simple Storage Service (Amazon S3) bucket, an Amazon EMR cluster, or a remote host that is accessed using a Secure Shell (SSH) connection. It is useful for bulk operations, rather than repeatedly calling INSERT command (specially when loading bulk data into a table). VACCUM command - After each bulk data load that modifies a significant amount of data, you need to perform a VACCUM command to reorganize your data and reclaim space after deletes. Data can also be exported out of Redshift using the UNLOAD command. This command can be used to generate delimited text files and store them on S3. You can monitor performance of a cluster and specific queries using Cloudwatch and Redshift web console You can use workload management (WLM) for Redshift clusters supporting multiple users, which will help you queue and prioritize queries. WLM allows you to configure multiple queues and set concurrency levels for queues as well. For eg. you can have one queue for long running queries and limit concurrency, while another queue for short running queries and high level of concurrency. Redshift allows you to create automated and manual snapshots just like RDS. Snapshots are durable stored in S3 RedShift is designed for single AZ deployments. However it can restore snapshots in another AZ in case of an outage Encryption - Supports encryption on data in transit using SSL encrypted connections For data at rest, it integrates with KMS and AWS cloudHSM for key management (AES 256) RedShift is PCI-DSS and HIPAA compliant Amazon Aurora Bespoke database engine created by AWS Only runs AWS infrastructure i.e cannot be installed locally on premise MySQL compatible i.e any of your MySQL databases can be migrated to Aurora very easily Combines speed and availability of high end databases with simplicity and cost effectiveness of open source databases Provides 5 times better performance than MySQL at one tenth the price Aurura Autoscaling - You can use Aurora Auto Scaling to automatically add or remove Aurora Replicas in response to changes in performance metrics specified by you. Aurora Replicas share the same underlying volume as the primary instance and are well suited for read scaling. With Aurora Auto Scaling, you can specify a desired value for predefined metrics of your Aurora Replicas such as average CPU utilization or average active connections. You can also create a custom metric for Aurora Replicas to use it with Aurora Auto Scaling. Aurora Auto Scaling adjusts the number of Aurora Replicas to keep the selected metric closest to the value specified by you. For example, an increase in traffic could cause the average CPU utilization of your Aurora Replicas to go up and beyond your specified value. New Aurora Replicas are automatically added by Aurora Auto Scaling to support this increased traffic. Similarly, when CPU utilization goes below your set value, Aurora Replicas are terminated so that you don't pay for unused DB instances. Aurora Auto Scaling works with Amazon CloudWatch to continuously monitor performance metrics of your Aurora Replicas. You can create an Aurora Auto Scaling policy for any of your existing or new MySQL-compatible Aurora DB clusters. Aurora Auto Scaling is available for both Aurora MySQL and Aurora PostgreSQL You define and apply a scaling policy to an Aurora DB cluster. The scaling policy defines the minimum and maximum number of Aurora Replicas that Aurora Auto Scaling can manage. Based on the policy, Aurora Auto Scaling adjusts the number of Aurora Replicas up or down in response to actual workloads, determined by using Amazon CloudWatch metrics and target values. Aurora data is stored in the cluster volume, which is a single, virtual volume that uses solid state drives (SSDs). A cluster volume consists of copies of the data across multiple Availability Zones in a single AWS Region. Because the data is automatically replicated across Availability Zones, your data is highly durable with less possibility of data loss. This replication also ensures that your database is more available during a failover. It does so because the data copies already exist in the other Availability Zones and continue to serve data requests to the DB instances in your DB cluster. The amount of replication is independent of the number of DB instances in your cluster. The Aurora shared storage architecture makes your data independent from the DB instances in the cluster. For example, you can add a DB instance quickly because Aurora doesn't make a new copy of the table data. Instead, the DB instance connects to the shared volume that already contains all your data. You can remove a DB instance from a cluster without removing any of the underlying data from the cluster. Only when you delete the entire cluster does Aurora remove the data. Aurora cluster volumes automatically grow as the amount of data in your database increases. An Aurora cluster volume can grow to a maximum size of 64 tebibytes (TiB). Table size is limited to the size of the cluster volume. That is, the maximum table size for a table in an Aurora DB cluster is 64 TiB. Aurora storage is self healing. Data blocks and disks are continuously scanned for errors and are repaired automatically. There are two types of Aurora replicas - Aurora replicas - Aurora Replicas are independent endpoints in an Aurora DB cluster, best used for scaling read operations and increasing availability Up to 15 Aurora Replicas can be distributed across the Availability Zones that a DB cluster spans within an AWS Region The DB cluster volume is made up of multiple copies of the data for the DB cluster. However, the data in the cluster volume is represented as a single, logical volume to the primary instance and to Aurora Replicas in the DB cluster. Aurora Replicas work well for read scaling because they are fully dedicated to read operations on your cluster volume. Write operations are managed by the primary instance. Because the cluster volume is shared among all DB instances in your DB cluster, minimal additional work is required to replicate a copy of the data for each Aurora Replica. To increase availability, you can use Aurora Replicas as failover targets. That is, if the primary instance fails, an Aurora Replica is promoted to the primary instance. There is a brief interruption during which read and write requests made to the primary instance fail with an exception, and the Aurora Replicas are rebooted. Failover logic - Tier 0>Tier 1>Tier 2 and so on MySQL read replica - Currently 5 is the limit Failover to a read replica is not automatic in this case Backup retention can vary from 1 day (default) to 35 days (max) Amazon DynamoDB Fully managed NoSQL database service that provides fast and low latency (single digit millisecond) performance that scales with ease. It supports document and key value data models. Provides consistent performance levels by automatically distributing the data traffic for a table multiple partitions, spread across three geographically distinct DCs. As your demand changes over time, y adjust the read and write capacity after the table has been created and DynamoDB will add/remove infrastructure and adjust internal partitioning accordingly. To maintain fast performance levels, data is always stored in SSD disk drives Performance metrics, including transaction rates can be monitored via Cloudwatch DynamoDB provided automatic high availability and durability protections by replicating data across multiple AZs within a region. DynamoDB data model - Components include - Tables (Collection of items) Items (collection of or or more attributes) Attributes (key-value pair) - Can be single value or multi valued set Primary key (to uniquely identify an item) Primary key cannot be changed after the table is created Consists of two attributes- Partition key - This is a hash key that DynamoDB creates. It is an unordered hash index of the primary key attribute Sort key - helps sort items within a range Combination of partition key and sort key identifies an item uniquely in a table. It is possible for two items to have the same partition key, but the sort keys must be different. A best practice to maximize your throughput is to distribute your requests across a full range of partition keys. In DynamoDB, attribute names and types do not have to be defined in advance (while creating the table). Only primary key needs to be defined in advance. Applications can connect to DynamoDB service endpoint using https or https and read, write, update, delete tables. DynamoDB provides a web service API that accepts requests in JSON format. Data types in DynamoDB - Scalar data types - Represents exactly one value and five scalar types - String Number Binary (binary data, images or compressed objects upto 400 KB in size) Boolean (true/false) Null (blank, empty or unknown state) Set data types - Represent a unique list of one or more scalar values and is the following types string set Number set Binary set Document data types - Represents multiple nested attributes, similar to the structure of a JSON file. Is of the following types- List - Ordered list of attributes of different data types Map - Unordered key/value pairs. Can be used to represent the structure of any JSON object. Provisioned Capacity - When you create a DynamoDB table, you are required to provision a certain amount of read and write capacity o handle expected workloads. Based on the configuration settings, DynamoDB provisions the right amount of infrastructure capacity to meet your requirements with sustained, low latency response time. Overall capacity is measured in read and write capacity units. These values can be scaled up or down using the UpdateTable action. Each operation against DynamoDB will consume some of the provisioned capacity units, depending upon the size of the item and other factors You can use Cloudwatch to monitor your Amazon DynamoDB capacity and make scaling decisions. Some metrics you can monitor - ConsumedReadCapacityUnits and ConsumedWriteCapacityUnits. If you exceed your provisioned capacity for a period of time, requests will be throttled and can be retrieved later Secondary Indexes - Lets you query your table based on an alternate key rather than just the primary key. It makes it easy to search large tables efficiently instead of running expensive scans to find items with specific attributes. It is of two types - Global Secondary Index - It is an index with a partition and sort key that is different from those in the table. It can be created or deleted on a table any time. There can be multiple global secondary indexes in a table Local Secondary index - It is an index that has the same partition key attribute as the primary key in the table, but a different sort key. It can only be created when the table is created. There can only be one local secondary index in a table. Reading and Writing data - DynamoDB allows three primary write API actions on a table- PutItem - Create a new item with one or more attributes. Requires only table name and primary keys-other attributes are optional UpdateItem - Finds existing items using the primary key and replace the attributes. Can be used to create items also, if they don't already exist. DeleteItem - Find an existing item using the primary key and delete it. The three actions above also support conditional expressions that allow you to perform additional validation before an action is applied - useful to prevent accidental overwrites or enforce some business logic checks Reading items can be done through the following - Calling the GetItem action for direct lookup in the table. This helps you retrieve items using a primary key and all the item's attributes are returned by default. You have an option to filter the results or select individual attributes. If the primary key contains only the partition key, GetItem will use this key to retrieve items. If the primary key contains both partition and sort key, then GetItem will need both to retrieve the items. Using search via the Scan action - With this, the scan operation will read every item in the table or a secondary index. By default, the scan operation returns all of the data attributes for every item in the table or index. Items can be filtered out using expressions, but this is a resource intensive operation. Using search via Query action - You can search using primary key values. Every query requires a partition key attribute name and a distinct value to search. For most operations, performing a query operation instead of scan will be the most efficient option. Use a query option when possible and avoid a scan on large tables or indices for only a small number of items. Consistency models - DynamoDB is a distributed system that stores multiple copies of an item across AZs in a region to provide high availability and durability. When an item is updated in DynamoDB, the replication can take some time to complete. There are two consistency models in DynamoDB Eventual Consistency - This is the default Consistency across all copies of data is usually achieved in one second. When you read data immediately after a write in DynamoDB, the response may include some stale data Strong Consistency - You can issue a strongly consistent read request (by using optional parameters in your request) Amazon DynamoDB returns a response with the most up to date data that reflects updates by all prior related write operations to which DynamoDB returned a successful response. This option may be less available in case of a network delay or outage. Pricing - DynamoDB is expensive for write operations and cheap for reads and should be preferred for read heavy databases. Pricing is based on the following - Throughput capacity provisioned - Read throughput capacity provisioned Write throughput capacity provisioned Storage Cost Scaling and Partitioning - DynamoDB table can scale horizontally through the use of partitions meet storage and performance requirements of your applications. Each individual partition represents a unit of compute and storage capacity. DynamoDB stores items for a single table across multiple partitions and it decides which partition to store which item in using the partition key. Items with the same partition key are stored in the same partition. DynamoDB provides push button scaling by just increasing the read and write capacity units. Unlike RDS, there is no downtime on the database while it scales. As the number of items in a table grows, additional partitions can be created by splitting existing partitions. Provisioned throughout configured for a table is also divided among partitions. There is no sharing of provisioned throughput across partitions. After a partition is split, it cannot be merged back together. with each additional partition created, its share of provisioned capacity is reduced. For partitions that are not fully using their provisioned capacity, DynamoDB provides some burst capacity to handle spikes in traffic. A portion of your unused capacity will be reserved to handle bursts during short periods. To maximize Amazon DynamoDB throughput, create tables with a partition key that has a large number of distinct values and ensure that the values are requested fairly uniformly. Adding a common element such as hashed is a common technique to improve partition distribution. Security - DynamoDB integrates with IAM service. You can create one or more policies that allow or deny specific operations on specific tables. You can also use conditions to restrict access to individual items or attributes Applications that need to read or write from DynamoDB need to obtain temporary or permanent access control keys. EC2 instance profiles or roles allow you to avoid storing sensitive keys in the configuration files that must then be secured For mobile applications, a best practice is to use a combination of web federation with AWS STS to issue temporary keys that expire after a short period of time. Using conditions in an IAM policy, you can restrict which action a user can perform,on which tables and to which attribute a user can read or write. Amazon DynamoDB streams - DynamoDB Streams provides a time ordered sequence of item level changes in any DynamoDB table. The changes are de-duplicated and stored for 24 hours. Each stream record represents a single data modification the Amazon DynamoDB table to which the stream belongs. Some records are also organized into groups called shards. Each shard acts as a container for multiple stream records . Shards live for a maximum of 24 hours. To build an application that reads from a shard, it is recommended to use the Amazon DynamoDB streams kinesis adapter. Some uses cases - An application in one AWS region modifies the data in a DynamoDB table. A second application in another AWS region reads these data modifications and writes the data to another table, creating a replica that stays in sync with the original table. A popular mobile app modifies data in a DynamoDB table, at the rate of thousands of updates per second. Another application captures and stores data about these updates, providing near real time usage metrics for the mobile app. A global multi-player game has a multi-master topology, storing data in multiple AWS regions. Each master stays in sync by consuming and replaying the changes that occur in the remote regions. An application automatically sends notifications to the mobile devices of all friends in a group as soon as one friend uploads a new picture. A new customer adds data to a DynamoDB table. This event invokes another application that sends a welcome email to the new customer. Amazon Elasticache ElastiCache is a web service that makes it easy to set up, manage, and scale a distributed in-memory data store or cache environment in the cloud. It provides a high-performance, scalable, and cost-effective caching solution, while removing the complexity associated with deploying and managing a distributed cache environment. It is suitable for read heavy workloads such as social networking, gaming, media sharing, Q&A portals and also for compute intensive workloads such as recommendation engines. Also, suitable where there are not any frequent changes to your database. Available for two different caching engines. Since it is protocol compliant with both engines, you only need to change the endpoint in your application configuration files and caching will be enabled. Your applications simply need information about the host names and port numbers of the ElastiCache nodes that you have deployed. The two caching engines are - Memcached - Simple to use memory object (key-value store) caching system that can be used to store arbitrary types of data Allows you to easily grow and shrink a cluster of memcached nodes to meet your demands. You can partition the cluster into shards and support parallel operations for high performance throughput Deals with objects as blobs that can be retrieved using a unique key A single memcached cluster can consist of upto 20 nodes. In this case, data is partitioned and is spread across the nodes. With automatic discovery of nodes within a cluster enabled for automatic discovery, so that no changes need to be made to your application when you add or remove nodes. Memcached clusters do not have any redundant data protection services (failovers in case of failures of nodes/outages) or native backup capabilities A new memcached cluster always starts empty Redis - Open source key value store Supports the ability to persist in memory data onto a disk. This allows to create snapshots that back up your data and recover/replicate from backups. Redis clusters can support upto 5 read replicas to offload read requests Using multi AZ replication groups, you can promote a read replica to the master node if the primary node fails. Thus, Redis provides you multi AZ redundancy. You can create multi-AZ replication groups to increase availability and minimize loss of data. Amazon Elasticache will update the domain name system entry of the new primary node to allow your application to continue processing without any configuration change, but a short disruption. Keep in mind that the replication is done asynchronously and there will be a short delay before data is available on all cluster nodes. It also has the capability to sort and rank data. Use case can be a leaderboard for a mobile application or serving as a high speed message broker for a distributed system. You can leverage a publisher and subscriber message abstraction that allows decouple components of your applications. This kind of an architecture gives you the flexibility to change how you consume messages in future without affecting the component that is producing the messages in the first place. Redis clusters are always made up of a single node. The single node handles the read and write transactions. However, you can have upto 5 read replicas that can handle the read-only requests. These read replicas along with the primary node form a "Replication group". This helps in horizontally scaling the cluster by writing code in your application offload reads to one of the read replicas. Redis clusters can be initiated from a backup, unlike memcached clusters which always start empty. You can reduce the impact of failure of a cache by using a large number of nodes with smaller capacity (such as t2) instead of a few larger nodes. In the event of a failure of a node, Elasticache will provision a replacement and add it to the cluster. During this time, your database will experience increased load since the requests at would have been cached will now need to read from the database. For Redis clusters, Elasticache will detect the failure and replace the primary node. If multi AZ is enabled, ad replica can be automatically promoted to the primary node. Support for vertical scaling is limited in Elasticache. You cannot resize your cluster if you want to change the cache node type or scale compute resources vertically. You will have to spin up a new cluster with the desired node type and redirect traffic to the new cluster. The "Auto discovery client" gives your application the ability to identify automatically all nodes in a cache cluster and to initiate and maintain connections to all these nodes. Auto discovery client is available for .Net, Java and PHP platforms Backup and Recovery - Redis clusters allow you to persist your data from in memory to disk using snapshots. Snapshots are stored on S3. Snapshots cannot be created for Memcached clusters. Each snapshot is a full clone of the data that can be used to recover to a specific point in time or create a copy for other purposes. Snapshots require compute and memory resources so performance may be impacted while a snapshot is being taken. It is recommended to take a snapshot from a read replica instead of the primary cluster to avoid performance issues Snapshots can be automatic or can be taken manually. If a snapshot is used to create a new redis cluster, the new cluster will have the same configuration as the source clusteryou can override these settings Access control - Access to the Elasticache cluster is controlled by restricting inbound access to the cluster using security groups or NACLs Individual nodes in a cluster can never be accessed from the internet or other EC2 instances outside the VPC where the cluster exists. Using IAM service, you can define policies that control which AWS users can manage the Elasticache infrastructure itself.
Page 11
AWS Route53
Amazon Route 53 is an authoritative DNS system - it provides a mechanism that developers can use to manage their public DNS names. It answers DNS queries translating domain names to IP addresses. Each domain name is registered in a central database known as the whois database. Subdomains are a method of sub-dividing the domain itself. For example, amazon.com would be a sub-domain of the TLD - .com. ; aws.amazon.com would be a sub-domain of the SLD - amazon.com. The leftmost portion of the domain is the most sepcific. DNS works from most to least specific i.e from left to right Hosts can be of carious types - web servers API hosts FTP hosts etc. Name Servers: - A computer designated to translate domain names to IP addresses. Name servers can be authoritative i.e they give answers to queries about domains under their control. If they are not authoritative, they point to other name servers or serve cached copies of other name servers data. Zone files - Simple text files that contain mappings between domain name and IP. They reside inside a name server and generally define the resources available under a specific domain or the place where one can go to get the information. The more zone files that a name server has, the more requests it will be able to answer authoritatively. Record types - Each zone contains records. A record is a single mapping between a resource and a name. This mapping can be a mapping of a name to an IP or a name to a resource such as a mail server or web server. Types of records - Start of authority (SOA) record - Mandatory record for all zone files Each zone contains a single SOA record Contains information such as - Name of DNS server for this zone Administrator of the zone Current version of the data file Default TTL value (in sec.) for resource records in the zone Etc. A and AAAA Records - Both types of records map a domain to IP address. A record maps to IPv4 and AAAA maps to IPv6 Canonical or "CNAME" Record- Defines an alias for the CNAME for your server (the domain name defined in the A or AAAA record) Mail Exchange (MX) Record- Used to define mail servers for a domain MX record should point to a host defined by a A/AAAA record and not one defined by a CNAME Name Server (NS) Record - Used by TLD servers to direct traffic to the DNS server that contains the authoritative DNS records Pointer (PTR) record - Reverse of an A record Maps IP to domain name Mainly used to check if the server name is associated with the IP address from where the connection was initiated. Sender Policy framework (SPF) - These records are used by mail servers to combat SPAM. This record tells a mail server which IP addresses are authorized to send an email from your domain name. Text Record Used to hold text information and provides the ability to hold arbitrary text with the host or other name such as human readable information about the server, network, data center or accounting information Service Record (SRV) - Specification of data in DNS defining the location(host name and port number) of servers for specified services Alias names - Unique to Route 53 Used to map resource record sets in your hosted zone to ELBs, S3 buckets, Cloudfront distributions etc. Difference between CNAME and alias names is that CNAMEs cannot be used for naked domain names. For eg. you cannot have a CNAME for http://acloudg.guru - it must be an "A record" or an alias. Exam Tip - Given a choice, always prefer an alias over a CNAME Alias resource record sets can save you time because Amazon Route 53 automatically recognizes changes in the record set that an alias record set refers to. For example if an alias record set for example.com points to an ELB at lb1-1234-use-east-1.amazonaws.com and the IP address of the ELB changes, route 53 will automatically reflect those changes in the DNS response for example.com without any changes to the hosted zones that contain the record sets for example.com Amazon Route 53 Overview - Amazon Route 53 is a highly available and scalable Domain Name System (DNS) web service. You can use Route 53 to perform three main functions in any combination: domain registration, DNS routing, and health checking. If you choose to use Route 53 for all three functions, perform the steps in this order: Register a domain name - If you want to create a website or a web application, you start by registering the name of your website, known as a domain name. If the domain name you want is already in use, you can try other names or try changing only the top-level domain, such as .com, to another top-level domain, such as .ninja or .hockey. When you register a domain with Route 53, the service automatically makes itself the DNS service for the domain by doing the following: Creates a hosted zone that has the same name as your domain. Assigns a set of four name servers to the hosted zone. When someone uses a browser to access your website, such as www.example.com, these name servers tell the browser where to find your resources, such as a web server or an Amazon S3 bucket. Gets the name servers from the hosted zone and adds them to the domain. If you already registered a domain name with another registrar, you can choose to transfer the domain registration to Route 53. This isn't required to use other Route 53 features (such as DNS service and health checks) DNS Service to route internet traffic to the resources for your domain Route 53 is an authoritative DNS service Health Checks Amazon Route 53 health checks monitor the health of your resources such as web servers and email servers. Route 53 sends automated requests over the internet to a resource, such as a web server, to verify that it's reachable, available, and functional. You can optionally configure Amazon CloudWatch alarms for your health checks, so that you receive notification when a resource becomes unavailable and choose to route internet traffic away from unhealthy resources. Health checks and DNS failover are major Route 53 tools that make your application highly available and resilient to failures. If you deploy your application in multiple availability zones and multiple regions, Route53 health check feature and only return healthy resources in response to DNS queries. There are three types of DNS failover configurations: Active-passive: Route 53 actively returns a primary resource. In case of failure, Route 53 returns the backup resource. Configured using a failover policy. Active-active: Route 53 actively returns more than one resource. In case of failure, Route 53 fails back to the healthy resource. Configured using any routing policy besides failover. Combination: Multiple routing policies (such as latency-based, weighted, etc.) are combined into a tree to configure more complex DNS failover. Note that Amazon Route 53 health checks are not triggered by DNS queries. They are run periodically by AWS and results are published to all the DNS servers. This way the name servers can be aware of unhealthy endpoint and can start diverting traffic to the healthy endpoint within minutes. Hosted zones - A container for records, which include information about how you want to route traffic for a domain (such as example.com) and all of its subdomains (such as www.example.com, retail.example.com, and seattle.accounting.example.com) A hosted zone has the same name as the corresponding domain. For example, the hosted zone for example.com might include a record that has information about routing traffic for www.example.com to a web server that has the IP address 192.0.2.243, and a record that has information about routing email for example.com to two email servers, mail1.example.com and mail2.example.com. Each email server also requires its own record. Two types of hosted zones - Private - Holds information about how you want to route traffic for a domain and its sub domains within one or more Amazon VPCs Public - Holds information about how you want to route traffic on the internet for a domain and its subdomains The resource record sets contained in a hosted zone but share the same suffic i.e you cannot have resource records for .com and .ca in the same hosted zone. Read page 235 on the Route53 chapter (marked part) - read once you've finished these notes Routing policies can be associated with health checks. The resource health check is considered first and then the defined routing policy is applied. Routing policies available on AWS - Simple Routing - (single record set) Default routing policy when you create a new resource Use for a single resource that performs a given function for your domain, for example, a web server that serves content for the example.com website. If you choose the simple routing policy in the Route 53 console, you can't create multiple records that have the same name and type, but you can specify multiple values in the same record, such as multiple IP addresses. If you choose the simple routing policy for an alias record, you can specify only one AWS resource or one record in the current hosted zone. If you specify multiple values in a record, Route 53 returns all values to the recursive resolver in random order, and the resolver returns the values to the client (such as a web browser) that submitted the DNS query Weighted Routing (multiple records with same name and type) Weighted routing lets you associate multiple resources with a single domain name (example.com) or subdomain name (acme.example.com) and choose how much traffic is routed to each resource. This can be useful for a variety of purposes, including load balancing across regions or testing new versions of software. Use this policy when you have multiple resources that perform the same function, but you want Route53 to distribute traffic in proportion to the weights assigned in the policy. To configure weighted routing, you create records that have the same name and type for each of your resources. You assign each record a relative weight that corresponds with how much traffic you want to send to each resource. Amazon Route 53 sends traffic to a resource based on the weight that you assign to the record as a proportion of the total weight for all records in the group: Weight of a specified record/sum of weights of all records For example, if you want to send a tiny portion of your traffic to one resource and the rest to another resource, you might specify weights of 1 and 255. The resource with a weight of 1 gets 1/256th of the traffic (1/1+255), and the other resource gets 255/256ths (255/1+255). You can gradually change the balance by changing the weights. If you want to stop sending traffic to a resource, you can change the weight for that record to 0. Latency based routing (Record set created for resource in each region where the resource exists ) If your application is hosted in multiple AWS Regions, you can improve performance for your users by serving their requests from the AWS Region that provides the lowest latency. To use latency-based routing, you create latency records for your resources in multiple AWS Regions. When Route 53 receives a DNS query for your domain or subdomain (example.com or apex.example.com), it determines which AWS Regions you've created latency records for, determines which region gives the user the lowest latency, and then selects a latency record for that region. Route 53 responds with the value from the selected record, such as the IP address for a web server. Latency between hosts on the internet can change over time as a result of changes in network connectivity and routing. Latency-based routing is based on latency measurements performed over a period of time, and the measurements reflect these changes. A request that is routed to the Oregon region this week might be routed to the Singapore region next week. Failover routing Failover routing lets you route traffic to a resource when the resource is healthy or to a different resource when the first resource is unhealthy. Helps you create an active-passive set up. The primary and secondary records can route traffic to anything from an Amazon S3 bucket that is configured as a website to a complex tree of records. You use health checks for failover routing and need to specify the following information to create a health check for an endpoint - Protocol - http or https IP address Host name (the domain name) Path Port You cannot create failover resource record sets for private hosted zones Geolocation based routing Geolocation routing lets you choose the resources that serve your traffic based on the geographic location of your users, meaning the location that DNS queries originate from. For example, you might want all queries from Europe to be routed to an ELB load balancer in the Frankfurt region, with local languages and pricing Use cases - You can also use geolocation routing to restrict distribution of content to only the locations in which you have distribution rights. Another possible use is for balancing load across endpoints in a predictable, easy-to-manage way, so that each user location is consistently routed to the same endpoint. You can specify geographic locations by continent, by country, or by state in the United States. If you create separate records for overlapping geographic regions—for example, one record for North America and one for Canada—priority goes to the smallest geographic region. This allows you to route some queries for a continent to one resource and to route queries for selected countries on that continent to a different resource. Geolocation works by mapping IP addresses to locations. However, some IP addresses aren't mapped to geographic locations, so even if you create geolocation records that cover all seven continents, Amazon Route 53 will receive some DNS queries from locations that it can't identify. You can create a default record that handles both queries from IP addresses that aren't mapped to any location and queries that come from locations that you haven't created geolocation records for. If you don't create a default record, Route 53 returns a "no answer" response for queries from those locations. You cannot create two geolocation resource record sets that specify the same geo location. You also cannot create geo location resource record sets that have the same names and types as those of the non geolocation resource record sets. Multi value answer routing (Multiple record sets) Multivalue answer routing lets you configure Amazon Route 53 to return multiple values, such as IP addresses for your web servers, in response to DNS queries. You can specify multiple values for almost any record, but multivalue answer routing also lets you check the health of each resource, so Route 53 returns only values for healthy resources. It's not a substitute for a load balancer, but the ability to return multiple health-checkable IP addresses is a way to use DNS to improve availability and load balancing. To route traffic approximately randomly to multiple resources, such as web servers, you create one multivalue answer record for each resource and, optionally, associate a Route 53 health check with each record. Route 53 responds to DNS queries with up to eight healthy records and gives different answers to different DNS resolvers. If a web server becomes unavailable after a resolver caches a response, client software can try another IP address in the response. Noteworthy points - If you don't associate a health check with a multivalue answer record, Route 53 always considers the record to be healthy. If you have eight or fewer healthy records, Route 53 responds to all DNS queries with all the healthy records. When all records are unhealthy, Route 53 responds to DNS queries with up to eight unhealthy records Each multi value answer record can have only one value Healthchecks can monitor - Endpoints Status of other health checks Status of a cloudwatch alarm
Page 12
Amazon Cloudwatch
Cloudwatch can help monitor your AWS resources thorough dashboards that you can create to - Create alarms and send notifications Create events that can trigger changes o resources being monitored based on rules you define Collect and track metrics Collect and maintain logs If a particular application specific metric that is not visible to AWS is the best metric to assess scaling needs, you can perform a PUT request to push the metric to cloudwatch and then use this custom metric to manage capacity. Cloudwatch supports multiple types of actions such as sending a notification on the simple notification service (SNS) or executing an Auto-scaling policy. Two types of monitoring - Basic - Free data collected every minutes only limited number of pre selected metrics (hypervisor visible metrics) Detailed Paid service data collected every 1 minute detailed metrics available There are 4 types of widgets that you can create on a CloudWatch dashboard - Text (using markdown language) Line Stacked area Number Amazon Cloudwatch supports an API that allows programs and scripts to PUT metrics into Amazon Cloudwatch as name-value pairs that can be used to create events and trigger alarms in the same manner as default Amazon Cloudwatch metrics Default metrics available in Cloudwatch for EC2 instances (everything else has to be monitored via custom metrics)- Network Disk CPU Status checks (both at instance as well as system/host level) Cloudwatch logs can be stored on Amazon S3 or Glacier and lifecycle policies can be applied. Cloudwatch logs agent is installed on EC2 instances to send logs to Amazon Cloudwatch Logs Each AWS account is limited to 5000 alarms and metrics data is retained for 2 weeks by default. If you need to to retain it for longer, move them to a persistent store like S3 or Glacier FAQs
Page 13
Other Exam Topics
Direct Connect AWS Direct Connect links your internal network to an AWS Direct Connect location over a standard Ethernet fiber-optic cable. One end of the cable is connected to your router, the other to an AWS Direct Connect router. With this connection, you can create virtual interfaces directly to public AWS services (for example, to Amazon S3) or to Amazon VPC, bypassing internet service providers in your network path. An AWS Direct Connect location provides access to AWS in the Region with which it is associated. You can use a single connection in a public Region or AWS GovCloud (US) to access public AWS services in all other public Regions. Benefits - Reduce costs when using large volumes of traffic Increased reliability increased bandwidth Difference between a VPN and AWS Direct connect - VPN can be used when you have an immediate need and can be configured in minutes VPN is used when you have low to modest bandwidth requirements and can tolerate inherent variability in internet based connectivity Direct Connect does not involve internet - instead it uses dedicated, private network connections between your intranet and Amazon VPC See Direct Connect architecture picture below Types of Connection - 1Gbps and 10Gbps ports are available. Speeds of 50Mbps, 100Mbps, 200Mbps, 300Mbps, 400Mbps, and 500Mbps can be ordered from any APN partners supporting AWS Direct Connect. Uses Ethernet VLAN trunking (802.1Q) The following are the key components that you use for AWS Direct Connect: Connections - Create a connection in an AWS Direct Connect location to establish a network connection from your premises to an AWS Region Virtual Interfaces - Create a virtual interface to enable access to AWS services. A public virtual interface enables access to public services, such as Amazon S3. A private virtual interface enables access to your VPC. FAQs Q. Can I use the same private network connection with Amazon Virtual Private Cloud (VPC) and other AWS services simultaneously? Yes. Each AWS Direct Connect connection can be configured with one or more virtual interfaces. Virtual interfaces may be configured to access AWS services such as Amazon EC2 and Amazon S3 using public IP space, or resources in a VPC using private IP space. Q. What are the technical requirements for the connection? AWS Direct Connect supports 1000BASE-LX or 10GBASE-LR connections over single mode fiber using Ethernet transport. Your device must support 802.1Q VLANs. See the AWS Direct Connect User Guide for more detailed requirements information. Q. Are connections to AWS Direct Connect redundant? Each connection consists of a single dedicated connection between ports on your router and an Amazon router. We recommend establishing a second connection if redundancy is required. When you request multiple ports at the same AWS Direct Connect location, they will be provisioned on redundant Amazon routers. To achieve high availability, we recommend you to have connections at multiple AWS Direct Connect locations. You can refer to this page to learn more about achieving highly available network connectivity. Q. Will I lose connectivity if my AWS Direct Connect link fails? If you have established a second AWS Direct Connect connection, traffic will failover to the second link automatically. We recommend enabling Bidirectional Forwarding Detection (BFD) when configuring your connections to ensure fast detection and failover. To achieve high availability, we recommend you to have connections at multiple AWS Direct Connect locations. You can refer to this page to learn more about achieving highly available network connectivity. If you have configured a back-up IPsec VPN connection instead, all VPC traffic will failover to the VPN connection automatically. Traffic to/from public resources such as Amazon S3 will be routed over the Internet. If you do not have a backup AWS Direct Connect link or a IPsec VPN link, then Amazon VPC traffic will be dropped in the event of a failure. Traffic to/from public resources will be routed over the Internet.
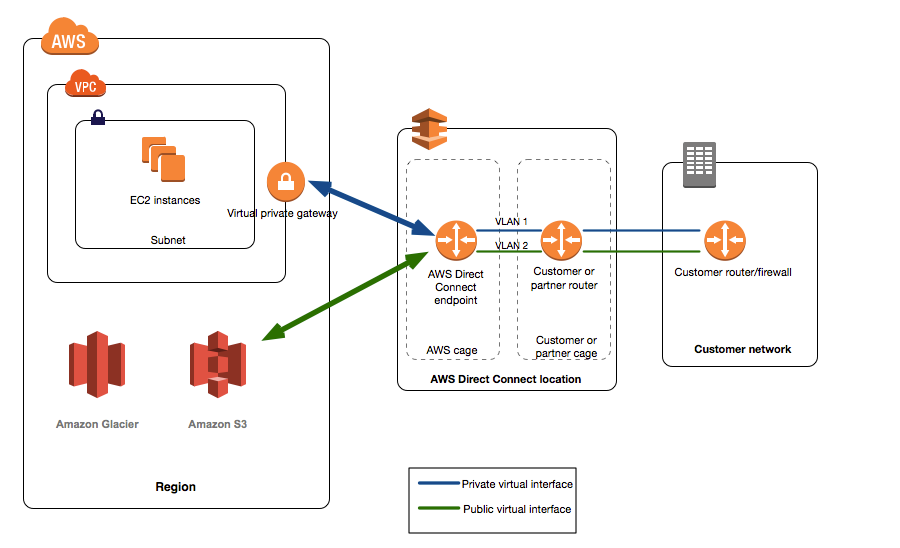{kind=link}
Amazon Simple Queuing Service Fast, reliable and fully managed message queing service which uses a pull based system to fetch and process messages. SQS makes it simple and cost effective to decouple components of a cloud application. You can use Amazon SQS to transmit any volume of data ant any level of thorughput, without losing messages or requiring other services to be continuosly available. It helps offload the administrative burden of operating and scaling a highly available messaging cluster at a pay per use pricing model. An SQS queue is a buffer between the application components that receive data and those compenents that process te data in your system. If your processing servers cannot process the work fast enough (eg. due to spike in traffic), the work is queued so that the servers can get it when they are ready. This means that the work is not lost due to insufficient resources. Amazon SQS ensures the delivery of each message at least once and supports multiple readers and writers interacting with the same queue. As single queue can be used simultaneously by many distributed application components, without the need for components to coordinate with each other to share the queue. Although, most of the time the message will be delivered to your application exactly once, your system should be designed idempotent which means that it must not be adversely impacted if the message is delivered more than once (in case of standard queues). SQS does not guarantee FIFO delivery of messages. If your system required orderly delivery of messages, you can place sequencing information in the messages so that you can re-order the messages when they are received (FIFO queue). Messages can be kept in the queue between 1 minute to 14 days. Default is 4 days. They can be retrieved programatically using the SQS API. Messages can be upto 256 KB in size in any format. Decoupling - Any component of the distributed application can store the messages and any other component can later retrieve these messages. Types of queues - Standard Default queue Lets you do almost unlimited number of transactions/sec Guarantees delivery of each message at least once, but ocsassionally, messages can be delivered more than once Does not guarantee FIFO delivery - only best effort Use cases - wherever your application can process messages that can arrive more than once and out of order - Decouple live user requests from intensive background work – Let users upload media while resizing or encoding it. Allocate tasks to multiple worker nodes – Process a high number of credit card validation requests. Batch messages for future processing – Schedule multiple entries to be added to a database. FIFO FIFO delivery is guaranteed Message is delivered once and remains in the queue till the receiver processes and deletes it - so no possibility of duplication Supports 300 messages/sec without batching and 3000 messages/sec with batching Use cases - wherever your application cannot afford duplication and messages arriving out of order - Ensure that user-entered commands are executed in the right order. Display the correct product price by sending price modifications in the right order. Prevent a student from enrolling in a course before registering for an account. Banking transactions Delay queues - They allow you to postpone delivery of new messages in queue for a specific number of seconds. If you create a delay queue, messages in that queue will not be visible to the customer for the duration of the delay period. To create a delay queue, use Createqueue and set the DelaySeconds attribute to any value between 0 to 900 (15 minutes). Default value of DelaySeconds is 0. To convert an existing queue to a delay queue, use the SetQueueAttributes to set the queue's DelaySeconds attribute. Delay queues are like visibility timeouts, except that delay queues hide the message from the customer as and when it is added to the queue, while visibility timers hide the message only after it is retrieved from the queue. Default visibility timer is 30 seconds and maximum is 12 hours. When a message is in the queue, but is neither delayed or in a visibility time out it is said to be in-flight. Messages are identified using a globally unique ID that SQS returns after the message is delivered to the queue. This ID is not required to perform any further actions on the message, but is useful to track if the message has been received by the queue. When you retrieve a message from a queue, the response includes a receipt handle which you must provide when deleting the message. Three identifiers used by SQS - Queue URL - You provide a unique name to any new queue when you create it. Amazon assigns each queue an identifier which must be provided whenever you need to perform any action on the queue. This identifier is called the queue URL Message ID - SQS assigns a unique ID to each message that it returns to you in the SendMessage response. The ID is useful in identifying messages, but remember that to delete a message, you need to provide the receipt handle instead of the message ID. Receipt handle - Each time you receive/retrieve a message from the queue, you receive a receipt handle for that specific message. To delete the message or change the visibility, you need to provide the receipt handle, not the message ID. This means that you always have to receive the message before you delete it - you cannot recall a message. Message Attributes - Message attributes allow you to provide structured metadata items such as timestamps, geospacial data, signatures and identifiers about the message. They are optional, but if used are sent with the message body. The receiver can use these attributes to decide upon how to handle the message without having to process the message body. Each message can have upto 10 attributes. Long polling - Your application keeping polling the queue for messages regardless of whether there are new messages in the queue or not. This can burn CPU cycles and can increase costs. With Long polling you can send a WaitTimeSeconds argument to the ReceiveMessage and the wait time can be upto 20 seconds. If there is no message in the queue, the call will wait for the wait time for a message to appear. If the message appears within this time, the call will immediately return the message, else will return without a message at the expiry of the wait time. Maximum retention period for a message in an SQS queue is 14 days. Dead Letter queues - Queues that other (source) queues can use as a target for messages that could not be successfully processed. You can then determine the cause of the failure by analyzing the messages in the dead letter queue. Access control in SQS - Allow you to assign policies to queues that grant specific interactions with other accounts without the account having to assume an IAM role from your account. Policies are written in JSON language. You can expose queues to other AWS accounts in the following scenarios - You want to grant another AWS account a particular type of access to the queue (eg. SendMessage) You want to grant access to another AWS account to your queue for a particular period of time You want to grant another AWS account access to your queue only if the requests come from your own EC2 instances You want to deny other AWS account access to your queue.
Amazon Simple Notification Service (SNS) Amazon Simple Notification Service (Amazon SNS) is a web service that coordinates and manages the delivery or sending of messages to subscribing endpoints or clients. In Amazon SNS, there are two types of clients—publishers and subscribers—also referred to as producers and consumers. Publishers communicate asynchronously with subscribers by producing and sending a message to a topic, which is a logical access point and communication channel. Subscribers (i.e., web servers, email addresses, Amazon SQS queues, AWS Lambda functions) consume or receive the message or notification over one of the supported protocols (i.e., Amazon SQS, HTTP/S, email, SMS, Lambda) when they are subscribed to the topic. When using Amazon SNS, you (as the owner) create a topic and control access to it by defining policies that determine which publishers and subscribers can communicate with the topic. A publisher sends messages to topics that they have created or to topics they have permission to publish to. Instead of including a specific destination address in each message, a publisher sends a message to the topic. Amazon SNS matches the topic to a list of subscribers who have subscribed to that topic, and delivers the message to each of those subscribers. Each topic has a unique name that identifies the Amazon SNS endpoint for publishers to post messages and subscribers to register for notifications. Subscribers receive all messages published to the topics to which they subscribe, and all subscribers to a topic receive the same messages. SNS works in the pay as you go model and can send notifications to apple, Andriod, Fire OS and Windows devices. When a message is published to an SNS topic that has a Lambda function subscribed to it, the Lambda function is invoked with the payload of the published message. The Lambda function receives the the message payload as an input parameter and can manipulate the information in the message, publish the message to other SNS topics or send the message to other AWS services. Common SNS Applications - SNS can support monitoring applications, workflow systems, time sensitive information updates, mobile applications and any other applications that that generates or consumes notifications. Some common deployment scenarios - Fanout - The "fanout" scenario is when an Amazon SNS message is sent to a topic and then replicated and pushed to multiple Amazon SQS queues, HTTP endpoints, or email addresses. This allows for parallel asynchronous processing. For example, you could develop an application that sends an Amazon SNS message to a topic whenever an order is placed for a product. Then, the Amazon SQS queues that are subscribed to that topic would receive identical notifications for the new order. The Amazon EC2 server instance attached to one of the queues could handle the processing or fulfillment of the order while the other server instance could be attached to a data warehouse for analysis of all orders received. Another way to use "fanout" is to replicate data sent to your production environment with your development environment. (also see pic below) Application and System alerts - Application and system alerts are notifications, triggered by predefined thresholds, sent to specified users by SMS and/or email. For example, since many AWS services use Amazon SNS, you can receive immediate notification when an event occurs, such as a specific change to your AWS Auto Scaling group. Push Email and Text Messaging - Push email and text messaging are two ways to transmit messages to individuals or groups via email and/or SMS. For example, you could use Amazon SNS to push targeted news headlines to subscribers by email or SMS. Upon receiving the email or SMS text, interested readers could then choose to learn more by visiting a website or launching an application. Mobile Push Notifications - Mobile push notifications enable you to send messages directly to mobile apps. For example, you could use Amazon SNS for sending notifications to an app, indicating that an update is available. The notification message can include a link to download and install the update. Message Durability - Amazon SNS provides durable storage of all messages that it receives. When Amazon SNS receives your Publish request, it stores multiple copies of your message to disk. Before Amazon SNS confirms to you that it received your request, it stores the message in multiple isolated locations known as Availability Zones. The message is stored in Availability Zones that are located within your chosen AWS Region SNS uses a push based model as opposed to SQS, which is a pull/polling based model.
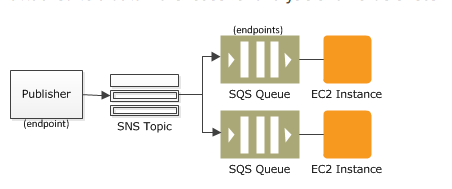{kind=link}
Amazon Simple Workflow Service (SWF) The Amazon Simple Workflow Service (Amazon SWF) makes it easy to build applications that coordinate work across distributed components. In Amazon SWF, a task represents a logical unit of work that is performed by a component of your application. Coordinating tasks across the application involves managing intertask dependencies, scheduling, and concurrency in accordance with the logical flow of the application. Amazon SWF gives you full control over implementing tasks and coordinating them without worrying about underlying complexities such as tracking their progress and maintaining their state. Use cases - Media processing Web application backends Business process workflows Analytic pipelines When using Amazon SWF, you implement workers to perform tasks. These workers can run either on cloud infrastructure, such as Amazon Elastic Compute Cloud (Amazon EC2), or on your own premises. You can create tasks that are long-running, or that may fail, time out, or require restarts—or that may complete with varying throughput and latency. Tasks can be executed by executable code, web service calls, human actions and scripts. Amazon SWF stores tasks and assigns them to workers when they are ready, tracks their progress, and maintains their state, including details on their completion. To coordinate tasks, you write a program that gets the latest state of each task from Amazon SWF and uses it to initiate subsequent tasks. Amazon SWF maintains an application's execution state durably so that the application is resilient to failures in individual components. With Amazon SWF, you can implement, deploy, scale, and modify these application components independently. SWF ensures that a task is assigned to a worker only once and is not duplicated. SWF terms - Workflows - Using the Amazon Simple Workflow Service (Amazon SWF), you can implement distributed, asynchronous applications as workflows. Workflows coordinate and manage the execution of activities that can be run asynchronously across multiple computing devices (i.e distributed computing) and that can feature both sequential and parallel processing. When designing a workflow, you analyze your application to identify its component tasks. In Amazon SWF, these tasks are represented by activities. The order in which activities are performed is determined by the workflow's coordination logic. Workflow Domains - Domains provide a way of scoping Amazon SWF resources within your AWS account. All the components of a workflow, such as the workflow type and activity types and the workflow execution itself, must be specified to be in a domain. It is possible to have more than one workflow in a domain; however, workflows in different domains can't interact with each other. When setting up a new workflow, before you set up any of the other workflow components you need to register a domain if you have not already done so. When you register a domain, you specify a workflow history retention period. This period is the length of time that Amazon SWF will continue to retain information about the workflow execution after the workflow execution is complete. You can register a domain using the AWS management console or using the RegisterDomain action in the Amazon SWF API Workflow history - The progress of every workflow execution is recorded in its workflow history, which Amazon SWF maintains. The workflow history is a detailed, complete, and consistent record of every event that occurred since the workflow execution started. An event represents a discrete change in your workflow execution's state, such as a new activity being scheduled or a running activity being completed. Maximum duration of a workflow execution can be 1 year. Actors - In the course of its operations, Amazon SWF interacts with a number of different types of programmatic actors. Amazon SWF brokers the interactions between workers and deciders. It allows the decider to get a consolidated view into the progress of tasks and initiate new tasks in an ongoing manner. Actors are of three types - Workflow Starters - A workflow starter is any application that can initiate workflow executions. In the e-commerce example, one workflow starter could be the website at which the customer places an order. Another workflow starter could be a mobile application or system used by a customer service representative to place the order on behalf of the customer. Deciders - A decider is an implementation of a workflow's coordination logic. Deciders control the flow of activity tasks in a workflow execution. Whenever a change occurs during a workflow execution, such as the completion of a task, a decision task including the entire workflow history will be passed to a decider. When the decider receives the decision task from Amazon SWF, it analyzes the workflow execution history to determine the next appropriate steps in the workflow execution. The decider communicates these steps back to Amazon SWF using decisions. Activity Workers - An activity worker is a process or thread that performs the activity tasks that are part of your workflow. The activity task represents one of the tasks that you identified in your application. Each activity worker polls Amazon SWF for new tasks that are appropriate for that activity worker to perform; certain tasks can be performed only by certain activity workers. After receiving a task, the activity worker processes the task to completion and then reports to Amazon SWF that the task was completed and provides the result. The activity worker then polls for a new task. The activity workers associated with a workflow execution continue in this way, processing tasks until the workflow execution itself is complete. In the e-commerce example, activity workers are independent processes and applications used by people, such as credit card processors and warehouse employees, that perform individual steps in the process. An activity worker represents a single computer process (or thread). Multiple activity workers can process tasks of the same activity type Tasks - Amazon SWF interacts with activity workers and deciders by providing them with work assignments known as tasks. There are three types of tasks in Amazon SWF: Activity task – An Activity task tells an activity worker to perform its function, such as to check inventory or charge a credit card. The activity task contains all the information that the activity worker needs to perform its function. Lambda task – A Lambda task is similar to an Activity task, but executes a Lambda function instead of a traditional Amazon SWF activity. Decision task – A Decision task tells a decider that the state of the workflow execution has changed so that the decider can determine the next activity that needs to be performed. The decision task contains the current workflow history. Essentially, every decision task gives the decider an opportunity to assess the workflow and provide direction back to Amazon SWF Task Lists - Task lists provide a way of organizing the various tasks associated with a workflow. You can think of task lists as similar to dynamic queues. When a task is scheduled in Amazon SWF, you can specify a queue (task list) to put it in. Similarly, when you poll Amazon SWF for a task you say which queue (task list) to get the task from. Task lists are dynamic in that you don't need to register a task list or explicitly create it through an action: simply scheduling a task creates the task list if it doesn't already exist. Long Polling - Deciders and activity workers communicate with Amazon SWF using long polling. The decider or activity worker periodically initiates communication with Amazon SWF, notifying Amazon SWF of its availability to accept a task, and then specifies a task list to get tasks from. If a task is available on the specified task list, Amazon SWF returns it immediately in the response. If no task is available, Amazon SWF holds the TCP connection open for up to 60 seconds so that, if a task becomes available during that time, it can be returned in the same connection. If no task becomes available within 60 seconds, it returns an empty response and closes the connection. Long polling works well for high-volume task processing. Deciders and activity workers can manage their own capacity, and it is easy to use when the deciders and activity workers are behind a firewall. Object Identifiers - The following list describes how Amazon SWF objects, such as workflow executions, are uniquely identified. Workflow Type – A registered workflow type is identified by its domain, name, and version. Workflow types are specified in the call to RegisterWorkflowType. Activity Type – A registered activity type is identified by its domain, name, and version. Activity types are specified in the call to RegisterActivityType. Decision Tasks and Activity Tasks – Each decision task and activity task is identified by a unique task token. The task token is generated by Amazon SWF and is returned with other information about the task in the response from PollForDecisionTask or PollForActivityTask. Although the token is most commonly used by the process that received the task, that process could pass the token to another process, which could then report the completion or failure of the task. Workflow Execution – A single execution of a workflow is identified by the domain, workflow ID, and run ID. The first two are parameters that are passed to StartWorkflowExecution. The run ID is returned by StartWorkflowExecution. Workflow execution closure - Once you start a workflow execution, it is open. An open workflow execution could be closed as completed, canceled, failed, or timed out. It could also be continued as a new execution, or it could be terminated. A workflow execution could be closed by the decider, by the person administering the workflow, or by Amazon SWF. Difference between SQS and SWF - SQS Message Oriented API You need to handle duplicate messages and need to ensure that the message is processed only once You need to implement your own application level tracking, especially if your application has multiple queues SWF Task oriented API Ensures task is assigned only once and is never duplicated Keeps track of all tasks and events for the application
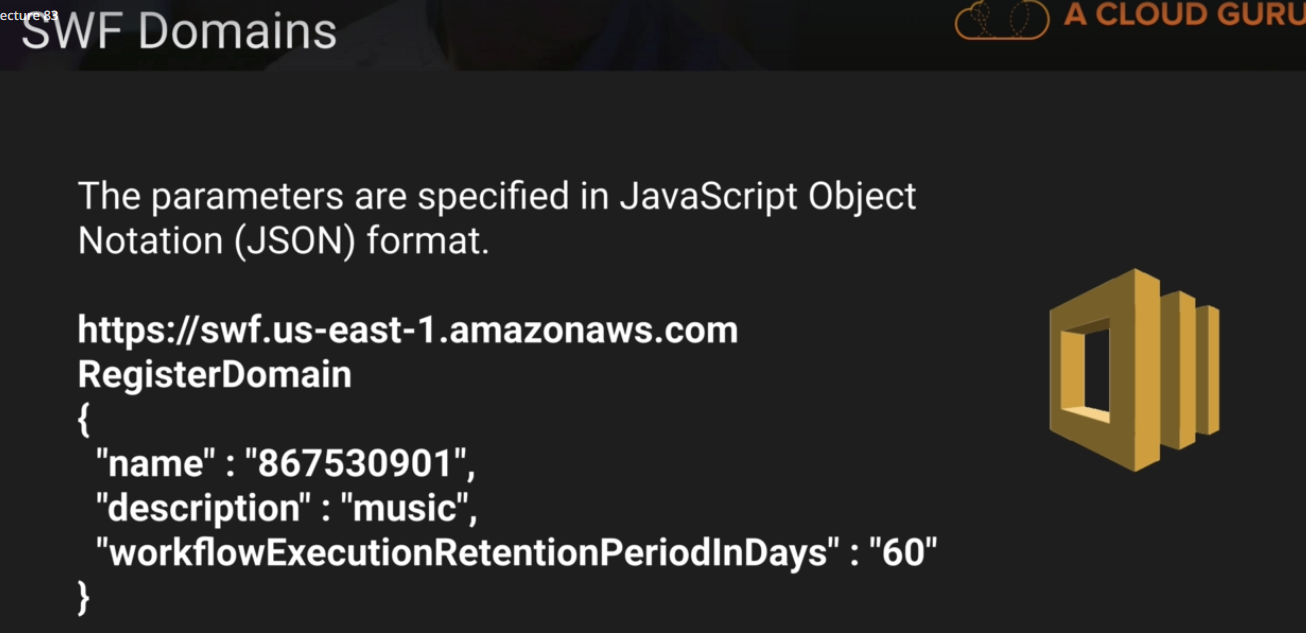{kind=link}
Kinesis See pic below (exam tip for Kinesis for data consumption and Redshift and mapReduce for processing) Kinesis is a platform for handling massive streaming data on AWS offering powerful services to make it easy to load and analyze streaming data and also providing the ability for you to build custom streaming data applications for specialized needs. Three services under Kinesis - Amazon Kinesis Firehose - Amazon Kinesis Data Firehose is a fully managed service for delivering real-time streaming data to destinations such as Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon Elasticsearch Service (Amazon ES), and Splunk. With Kinesis Data Firehose, you don't need to write applications code or manage resources. You configure your data producers or clients to send data to Kinesis Data Firehose using an AWS API call, and it automatically delivers the data to the destination that you specified (see pic below) Data flow in firehose - For Amazon S3 destinations, streaming data is delivered to your S3 bucket. If data transformation is enabled, you can optionally back up source data to another Amazon S3 bucket. For Amazon Redshift destinations, streaming data is delivered to your S3 bucket first. Kinesis Data Firehose then issues an Amazon Redshift COPY command to load data from your S3 bucket to your Amazon Redshift cluster. If data transformation is enabled, you can optionally back up source data to another Amazon S3 bucket. For Amazon ES destinations, streaming data is delivered to your Amazon ES cluster, and it can optionally be backed up to your S3 bucket concurrently. For Splunk destinations, streaming data is delivered to Splunk, and it can optionally be backed up to your S3 bucket concurrently. Amazon Kinesis data streams - You can use Amazon Kinesis Data Streams to collect and process large streams of data records in real time. You can create data-processing applications, known as Kinesis Data Streams applications. A typical Kinesis Data Streams application reads data from a data stream as data records. You can use Kinesis Data Streams for rapid and continuous data intake and aggregation. The type of data used can include IT infrastructure log data, application logs, social media, market data feeds, and web clickstream data. Because the response time for the data intake and processing is in real time, the processing is typically lightweight. The producers continually push data to Kinesis Data Streams, and the consumers process the data in real time. Consumers (such as a custom application running on Amazon EC2 or an Amazon Kinesis Data Firehose delivery stream) can store their results using an AWS service such as Amazon DynamoDB, Amazon Redshift, or Amazon S3. A Kinesis data stream is a set of shards. Each shard has a sequence of data records. Each data record has a sequence number that is assigned by Kinesis Data Streams. Shards enable kinesis data streams to support nearly limitless data streams by distributing incoming data across a number of shards. If any shard becomes too busy, it can be divided into more shards to distribute the load further. The processing is then executed on the consumer which read data from the shards and run the kinesis streams application. A stream's data retention period is 24 hours by default, but can be increased upto 7 days. Data capacity of a stream is a function of the number of shards that you specify for the stream. The total capacity of the stream is the sum of capacities of the individual shards. See picture below Amazon Kinesis video streams - Amazon Kinesis Video Streams is a fully managed AWS service that you can use to stream live video from devices to the AWS Cloud, or build applications for real-time video processing or batch-oriented video analytics. Kinesis Video Streams isn't just storage for video data. You can use it to watch your video streams in real time as they are received in the cloud. You can either monitor your live streams in the AWS Management Console, or develop your own monitoring application that uses the Kinesis Video Streams API library to display live video. You can use Kinesis Video Streams to capture massive amounts of live video data from millions of sources, including smartphones, security cameras, webcams, cameras embedded in cars, drones, and other sources. Amazon Kinesis Analytics - With Amazon Kinesis Data Analytics, you can process and analyze streaming data using standard SQL. The service enables you to quickly author and run powerful SQL code against streaming sources to perform time series analytics, feed real-time dashboards, and create real-time metrics. To get started with Kinesis Data Analytics, you create a Kinesis data analytics application that continuously reads and processes streaming data. The service supports ingesting data from Amazon Kinesis Data Streams and Amazon Kinesis Data Firehose streaming sources. Then, you author your SQL code using the interactive editor and test it with live streaming data. You can also configure destinations where you want Kinesis Data Analytics to send the results. Kinesis Data Analytics supports Amazon Kinesis Data Firehose (Amazon S3, Amazon Redshift, and Amazon Elasticsearch Service), AWS Lambda, and Amazon Kinesis Data Streams as destinations. Use cases - Data ingestion - User data from highly trafficed websites, input data from thousands of monitoring devices, or any sources of huge streams - Amazon Firehose ensures that all your data is successfully stored in your AWS infrastructure Real time processing of massive data streams - Amazon kinesis data streams helps you gather knowledge from big data streams on a real time basis. Note - amazon kinesis is ideally suited for ingesting and processing streams of data and is less appropriate for batch jobs such as nightly ETL processes. For these types of batch workloads, use AWS Data Pipeline.
{kind=link}
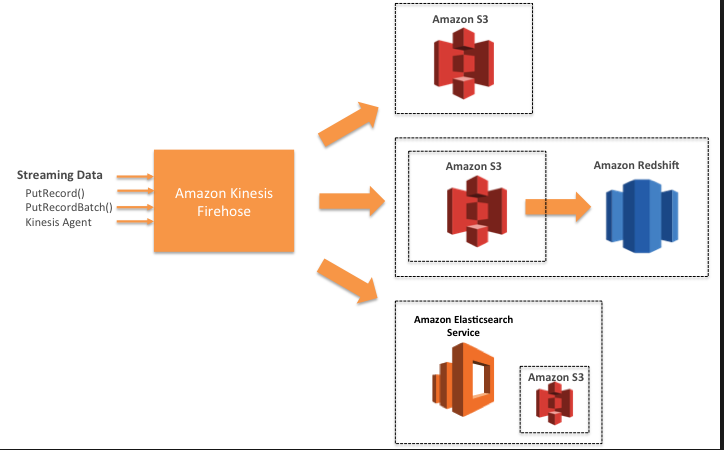{kind=link}
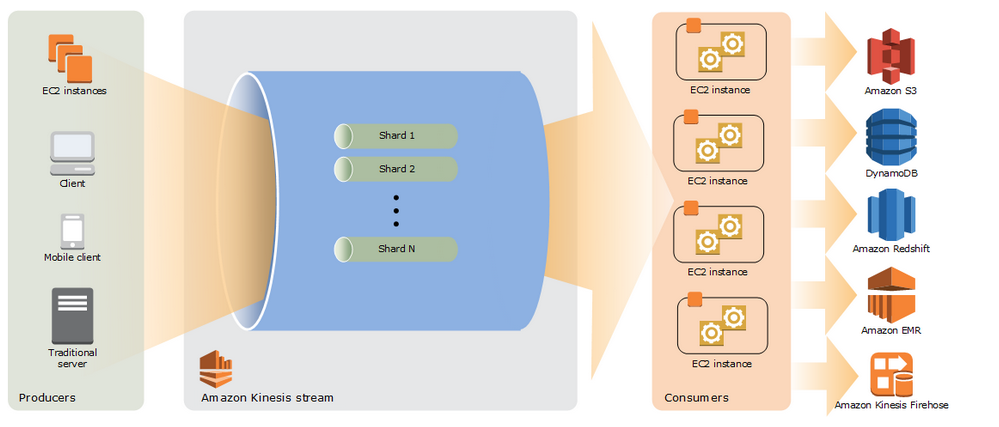{kind=link}
Elastic Transcoder Amazon Elastic Transcoder lets you convert media files that you have stored in Amazon Simple Storage Service (Amazon S3) into media files in the formats required by consumer playback devices You can convert large, high-quality digital media files into formats that users can play back on mobile devices, tablets, web browsers, and connected televisions. Provides transcoding presets for popular output formats which means that you do not have to guess about which settings work best on a particular device. Billing is based on - The number of minutes you transcode Resolution at which you transcode. Elastic transcoder has four components - Jobs do the work of transcoding. Each job converts one file into up to 30 formats. For example, if you want to convert a media file into six different formats, you can create files in all six formats by creating a single job. When you create a job, you specify the name of the file that you want to transcode, the names that you want Elastic Transcoder to give to the transcoded files, and several other settings. Pipelines are queues that manage your transcoding jobs. When you create a job, you specify which pipeline you want to add the job to. Elastic Transcoder starts processing the jobs in a pipeline in the order in which you added them. If you configure a job to transcode into more than one format, Elastic Transcoder creates the files for each format in the order in which you specify the formats in the job. One common configuration is to create two pipelines—one for standard-priority jobs, and one for high-priority jobs. Most jobs go into the standard-priority pipeline; you use the high-priority pipeline only when you need to transcode a file immediately. Presets are templates that contain most of the settings for transcoding media files from one format to another. Elastic Transcoder includes some default presets for common formats, for example, several iPod and iPhone versions. You can also create your own presets for formats that aren't included among the default presets. You specify which preset you want to use when you create a job. Notifications let you optionally configure Elastic Transcoder and Amazon Simple Notification Service to keep you apprised of the status of a job: when Elastic Transcoder starts processing the job, when Elastic Transcoder finishes the job, and whether Elastic Transcoder encounters warning or error conditions during processing. Notifications eliminate the need for polling to determine when a job has finished. You configure notifications when you create a pipeline.
API Gateway Amazon API Gateway is a fully managed AWS service that enables you to create, publish, maintain, monitor, and secure your own REST and WebSocket APIs at any scale. With a few clicks in the AWS management console, you can create APIs that can act as a frontdoor for your application to access data, business logic or functionality from back end services such as applications running on EC2, code running on Lambda or any other web application. See API picture below API Caching - You can enable API caching in Amazon API Gateway to cache your endpoint's responses. With caching, you can reduce the number of calls made to your endpoint and also improve the latency of requests to your API. When you enable caching for a stage, API Gateway caches responses from your endpoint for a specified time-to-live (TTL) period, in seconds. API Gateway then responds to the request by looking up the endpoint response from the cache instead of making a request to your endpoint. The default TTL value for API caching is 300 seconds. The maximum TTL value is 3600 seconds. TTL=0 means caching is disabled. API gateway noteworthy points - Low cost and efficient Scales Effortlessly You can throttle requests to prevent attacks Connect to cloudwatch to log all requests There are two kinds of developers who use API Gateway: API developers and app developers. An API developer creates and deploys an API to enable the required functionality in API Gateway. The API developer must be an IAM user in the AWS account that owns the API. An app developer builds a functioning application to call AWS services by invoking a WebSocket or REST API created by an API developer in API Gateway. The app developer is the customer of the API developer. The app developer does not need to have an AWS account, provided that the API either does not require IAM permissions or supports authorization of users through third-party federated identity providers supported by Amazon Cognito user pool identity federation. Such identity providers include Amazon, Amazon Cognito User Pools, Facebook, and Google. Same Origin Policy and CORS - In computing, the same origin policy is an important concept in a web application security model. Under this policy, a web browser permits scripts contained in a first web page to access data on the second webpage, but only if both pages have the same origin. Cross Origin Resource sharing (CORS) is one way that the server at the other end (not the client code in the browser) can relax the same policy. CORS is a mechanism that allows restricted resources (eg fonts) on a webpage to be requested from another domain outside the domain from which the first resource was served. If you get an error - "Origin policy cannot be read at the remote resource" - this means that you need to enable CORS on the API gateway.
{kind=link}
OpsWorks AWS OpsWorks is a configuration management service that helps you configure and operate applications in a cloud enterprise by using Puppet or Chef. Chef and Puppet are automation platforms that allow you to use code to automate the configurations of your servers. OpsWorks lets you use Chef and Puppet to automate how servers are configured, deployed, and managed across your Amazon EC2 instances or on-premises compute environments. It is an orchestration service AWS opsworks will work with applications with any level of complexity and is independent of any particular architectural pattern. Supports both Linux and Windows servers, including EC2 instances or on-premise servers - thus helping organizations use a single configuration management service to deploy and operate applications in a hybrid architecture. Exam tip - Look for terms - "Puppet", "Chef", "Recipes" or "Workbooks" and think Opsworks OpsWorks comes in three flavours - AWS OpsWorks stacks - Cloud-based computing usually involves groups of AWS resources, such as EC2 instances and Amazon Relational Database Service (RDS) instances. For example, a web application typically requires application servers, database servers, load balancers, and other resources. This group of instances is typically called a stack. AWS OpsWorks Stacks, the original service, provides a simple and flexible way to create and manage stacks and applications. AWS OpsWorks Stacks lets you deploy and monitor applications in your stacks. You can create stacks that help you manage cloud resources in specialized groups called layers. A layer represents a set of EC2 instances that serve a particular purpose, such as serving applications or hosting a database server. Layers depend on Chef recipes to handle tasks such as installing packages on instances, deploying apps, and running scripts. One key feature is a set of lifecycle events that automatically run on a specified set of recipes at the appropriate time on each instance. OpsWorks for Puppet enterprise - OpsWorks for Puppet Enterprise lets you create AWS-managed Puppet master servers. A Puppet master server manages nodes in your infrastructure, stores facts about those nodes, and serves as a central repository for your Puppet modules. Modules are reusable, shareable units of Puppet code that contain instructions about how your infrastructure should be configured. OpsWorks for Chef automate - AWS OpsWorks for Chef Automate lets you create AWS-managed Chef servers that include Chef Automate premium features, and use the Chef DK and other Chef tooling to manage them. A Chef server manages nodes in your environment, stores information about those nodes, and serves as a central repository for your Chef cookbooks. The cookbooks contain recipes that are run by the chef-client agent on each node that you manage by using Chef. OpsWorks sends all your resource metrics to CloudWatch. It also provides custom metrics and has capability to provide metrics for each instance in the stack Use cases - Host multi tier web applications Support continuous integration using DevOps. Everything in your environment can be automated.
AWS Organizations Account Management service that let's you consolidate multiple AWS accounts into an organization that you create and centrally manage Available in two feature sets - Consolidated Billing (see first three pics below) - Advantages - One bill per AWS account Very easy to track charges and allocate cost Volume pricing discount Automate AWS account creation and management Centralized management of multiple AWS accounts by creating groups of accounts and applying policies to the group. Allows you to centrally manage policies across multiple accounts without requiring custom scripts and manual processes. Controlled access - You can create service control policies (SCP) that centrally control AWS service use across AWS multiple AWS accounts. For eg. you could deny access to Kinesis to your HR group. Even if IAM allows it, SCP would override it. You can deny specific APIs. Best Practices - Use MFA on root account Use strong and complex password for root account Paying account should be used for billing purposes only. Do not deploy resources on the paying account Other things to note - When monitoring is enabled on paying account, billing data from all linked accounts is included. However, you can still configure billing alerts per individual account. Cloudtrail is enabled per AWS account and is enabled per region. But you can consolidate logs using an S3 bucket - Turn Cloudtrail on in the paying account Create a bucket policy that allows cross account access Turn Cloudtrail on in the other accounts and use the bucket in the paying account. All features See pic below on AWS Organizations structure You can apply policies to the following entities in your organization: A root – A policy applied to a root applies to all accounts in the organization An OU – A policy applied to an OU applies to all accounts in the OU and to any child OUs An account – A policy applied to an account applies only to that one account
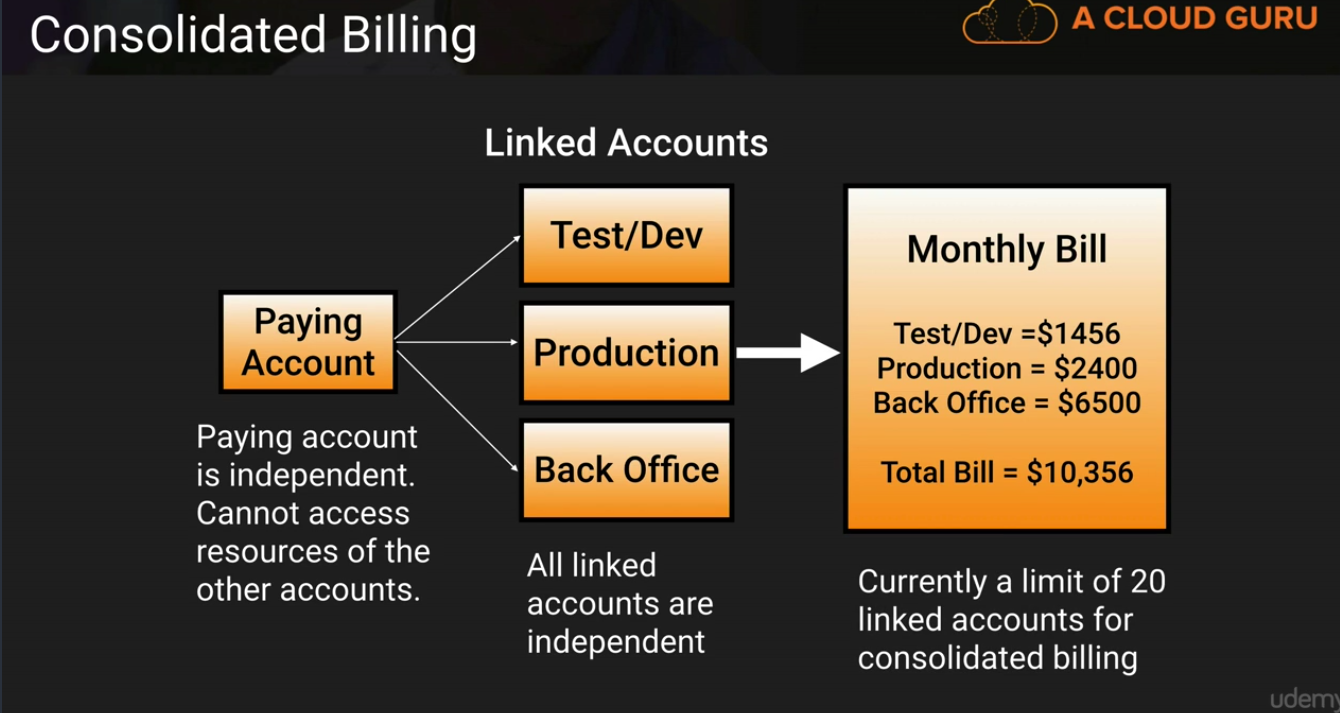{kind=link}
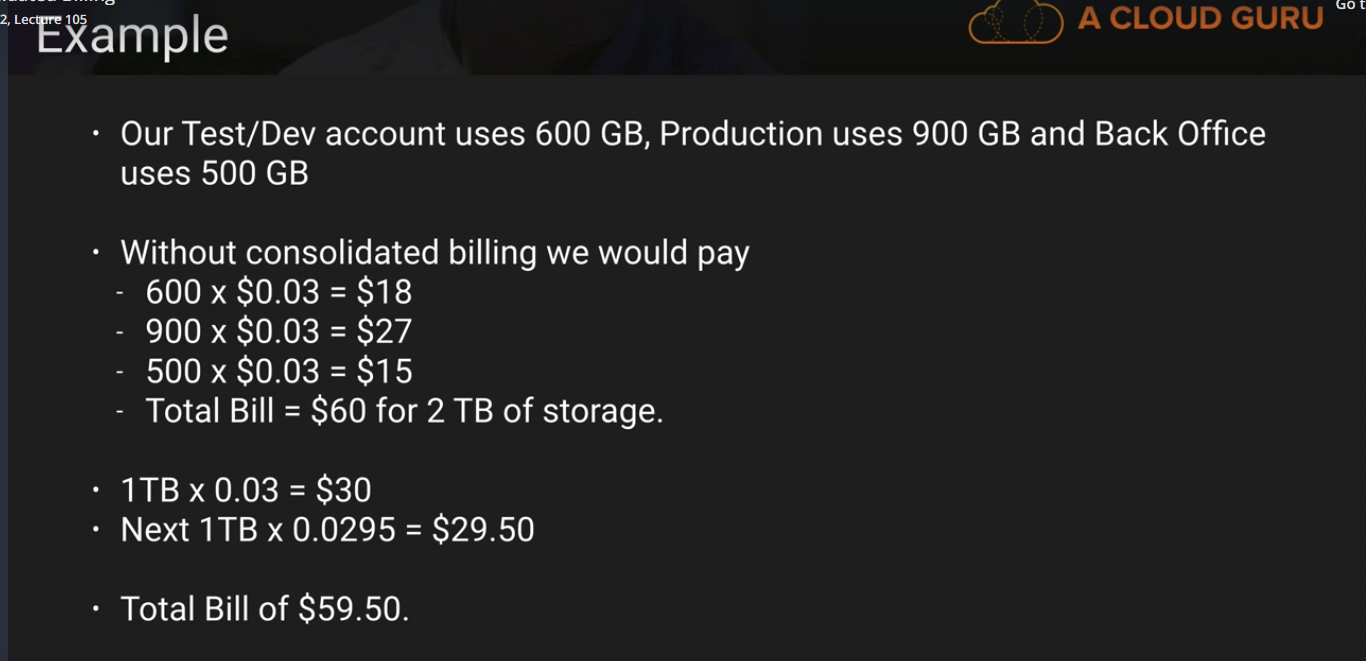{kind=link}
{kind=link}
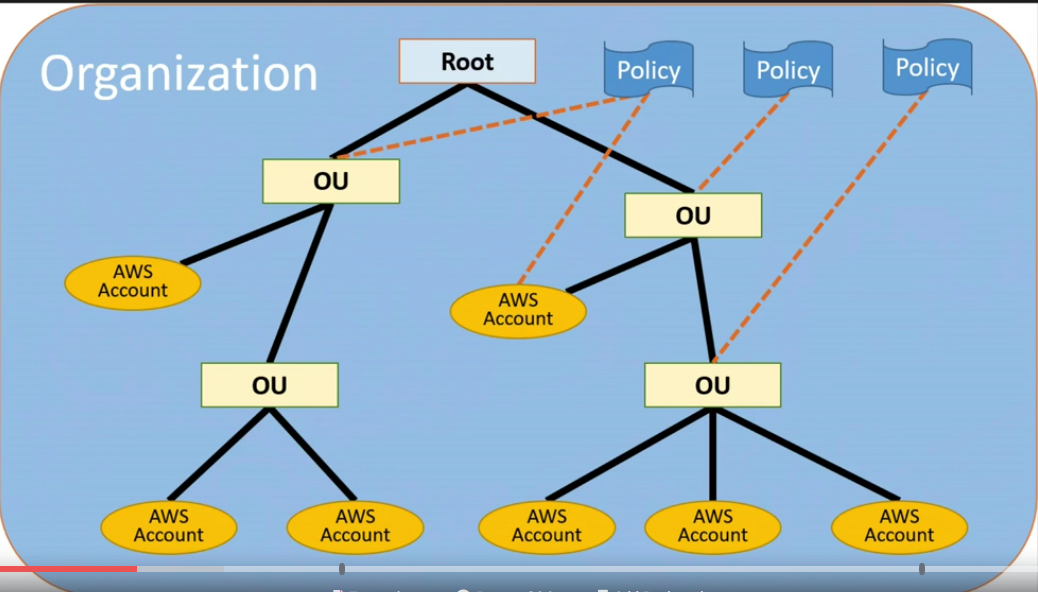{kind=link}
Tagging and Resource Groups Tags - Key-value pairs (Metadata) - Tags can sometimes be inherited. Autoscaling, Cloudformation and Elasticbeanstalk can create other resources. Tags are case sensitive - if you add a tag "name", it will not work. If you add "Name" it will work. Resource groups - They make it easy to group resources using tags that are assigned to them. You can group resources that share one or more tags. They contain information such as Region Name Health Checks Specific information such as For EC2 - Public and private IPs For ELBs - Port configurations For RDS - Database engines etc. Resource Groups are of two types - Classic Resource groups Are global AWS Systems manager (through create a group option in resource groups) On a per region basis You can view insights such as inventory, compliance of attached resources to this group and use other built in insights You can also execute automation on the group such as creating images of all EC2 instances in the group
Workspaces Amazon WorkSpaces is a managed, secure cloud desktop service. You can use Amazon WorkSpaces to provision either Windows or Linux desktops in just a few minutes and quickly scale to provide thousands of desktops to workers across the globe. You can pay either monthly or hourly, just for the WorkSpaces you launch, which helps you save money when compared to traditional desktops and on-premises VDI solutions. Users can access their virtual desktops from multiple devices or web browsers. Features - Choose your operating system (Windows or Amazon Linux) and select from a range of hardware configurations, software configurations, and AWS regions. For more information, see Amazon WorkSpaces Bundles. Connect to your WorkSpace and pick up from right where you left off. Amazon WorkSpaces provides a persistent desktop experience. Users can connect from their tablet, desktop or any supported device using the free Amazon workspaces client application. Amazon WorkSpaces provides the flexibility of either monthly or hourly billing for WorkSpaces. For more information, see Amazon WorkSpaces Pricing. Deploy and manage applications for your WorkSpaces by using Amazon WorkSpaces Application Manager (Amazon WAM). For Windows desktops, you can bring your own licenses and applications, or purchase them from the AWS Marketplace for Desktop Apps. Create a standalone managed directory for your users, or connect your WorkSpaces to your on-premises directory so that your users can use their existing credentials to obtain seamless access to corporate resources. Use the same tools to manage WorkSpaces that you use to manage on-premises desktops. Use multi-factor authentication (MFA) for additional security. Use AWS Key Management Service (AWS KMS) to encrypt data at rest, disk I/O, and volume snapshots. Control the IP addresses from which users are allowed to access their WorkSpaces. You don't need to have an AWS account to access workspaces. You can just connect to a workspace using the free Amazon workspaces client application once you have subscribed to the workspace service. You cannot use a web browser to connect to Amazon Linux WorkSpaces. There are client applications for the following devices: Windows computers Mac computers Chromebooks iPads Android tablets Fire tablets Zero client devices On Windows, macOS, and Linux PCs, you can use the following web browsers to connect to Windows WorkSpaces: Chrome 53 and later Firefox 49 and later By default, users can personalize their workspaces (settings, favourites, wallpaper etc.), but this can be locked down by the administrator. By default, you will be given a local administrator access to install your own applications. This can also be restricted by the administrator. All data on D: is backed up every 12 hours. All critical data should thus be kept in the D:
ECS See pic below for Virtualization Vs Containerization Containerization benefits Escape from dependency hell Consistent progression from DEV-TEST-QA-PROD Isolation - Performance or stability issues with App A in container A would not impact App B in container B Much better resource management Extreme code portability Micro services Docker components - Docker Image - Rather than containing the entire OS, it only contains files that are needed to boot a container. It is a read only template that you use to create containers. It is an ordered collection of root filesystem changes and the corresponding execution parameters for use within a container runtime Docker container - Contains everything you need to for an application to run. Each container is created from a docker image and these docker containers can be run, started, stopped, moved and deleted. Each container is an isolated and secure application platform Layers/Union file system - Docker file - Stores instructions to run commands.An image is creater from a Dockerfile which is a plaintext file that specifies components that are to be included in the container. Docker daeomon/engine - Runs on Linux to provide capability to run, ship and build containers Docker client - Interface between user and the docker engine to create, delete, manipulate docker containers Docker registries/docker hub - Public/Private stores from where you upload or download your images. eg. Dockerhub or AWS ECR ECS - Amazon Elastic Container Service (Amazon ECS) is a highly scalable, fast, container management service that makes it easy to run, stop, and manage Docker containers on a cluster. You can host your cluster on a serverless infrastructure that is managed by Amazon ECS by launching your services or tasks using the Fargate launch type. For more control you can host your tasks on a cluster of Amazon Elastic Compute Cloud (Amazon EC2) instances that you manage by using the EC2 launch type. Amazon ECS lets you launch and stop container-based applications with simple API calls, allows you to get the state of your cluster from a centralized service, and gives you access to many familiar Amazon EC2 features. You can use Amazon ECS to schedule the placement of containers across your cluster based on your resource needs, isolation policies, and availability requirements. Amazon ECS eliminates the need for you to operate your own cluster management and configuration management systems or worry about scaling your management infrastructure. It is a regional service that you can use in one or more AZs in an existing or new VPC to schedule placement of containers across your cluster based on resource needs, isolation policies and availability requirements Can be used to create a consistent deployment and build experience, manage and scale ETL (Extract, Transform and Load) workloads and build sophisticated application architectures on a microservices model Components/Features of ECS - Containers and Images- To deploy applications on Amazon ECS, your application components must be architected to run in containers. A Docker container is a standardized unit of software development, containing everything that your software application needs to run: code, runtime, system tools, system libraries, etc. Containers are created from a read-only template called an image. To deploy applications on Amazon ECS, your application components must be architected to run in containers. Images are typically built from a Dockerfile, a plain text file that specifies all of the components that are included in the container. These images are then stored in a registry from which they can be downloaded and run on your cluster (see pic below) ECS Task definition - To prepare your application to run on Amazon ECS, you create a task definition. The task definition is a text file, in JSON format, that describes one or more containers, up to a maximum of ten, that form your application. It can be thought of as a blueprint for your application. Task definitions specify various parameters for your application. Examples of task definition parameters are which images to use with the containers in your task which containers to use, how much CPU and memory to use with each container whether containers are linked together in a task which launch type to use, which ports should be opened for your application what data volumes should be used with the containers in the task. docker networking mode to use with containers in your task whether the task should continue if the container finishes or fails the command the container should run when it is started any IAM roles your tasks should use for permissions what (if any) environment variable should be passed to the container when it starts Clusters - When you run tasks using Amazon ECS, you place them on a cluster, which is a logical grouping of resources. When using the Fargate launch type with tasks within your cluster, Amazon ECS manages your cluster resources. Amazon ECS downloads your container images from a registry that you specify, and runs those images within your cluster. When you first use the ECS service, a default cluster is created for you, but you can create multiple clusters in your account to keep resources separate. Clusters can contain multiple different container instance types They are region specific Container instances can be a part of only one cluster at a time. You can create IAM policies for your cluster to restrict user access to specific clusters. Tasks and Scheduling - Amazon Elastic Container Service (Amazon ECS) is a shared state, optimistic concurrency system that provides flexible scheduling capabilities for your tasks and containers. The Amazon ECS schedulers leverage the same cluster state information provided by the Amazon ECS API to make appropriate placement decisions. Two types of schedulers - Service Scheduler - The service scheduler is ideally suited for long running stateless services and applications The service scheduler ensures that the scheduling strategy you specify is followed and reschedules tasks when a task fails (for example, if the underlying infrastructure fails for some reason). The service scheduler optionally also makes sure that tasks are registered against an Elastic Load Balancing load balancer. Custom Scheduler - Amazon ECS allows you to create your own schedulers that meet the needs of your business, You can also leverage third party schedulers such as Blox Custom schedulers are only compatible with tasks using the EC2 launch type. ECS container agent - The container agent runs on each infrastructure resource within an Amazon ECS cluster. It sends information about the resource's current running tasks and resource utilization to Amazon ECS starts and stops tasks whenever it receives a request from Amazon ECS. It only supported on EC2 instances. It is pre installed on special ECS AMIs and can be manually installed on Linus based instances - Amazon Linux, Ubuntu, RedHat, CentOS etc. It does not work with Windows ECR - Amazon EC2 container registry is a managed AWS docker registry that is secure, scalable and reliable. Amazon ECR supports private docker repositories with resource based permissions using IAM so that specific users or EC2 instances can access repositories and images. Developers can use docker CLI to push, pull or manage images. An Amazon ECS service allows you to run a specified (or desired count) of EC2 instances of a task definition in an ECS cluster These are like autoscaling groups for an ECS cluster. If a task would fail or stop, ECS service scheduler would launch another instance of your task definition to replace it and maintain desired count of tasks in service. ECS and Security - EC2 instances use an IAM role to access ECS ECS tasks use an IAM role to access services and resources Security groups are attached at instance level (i.e host - NOT the task or container) You can access and configure the OS of your EC2 instance in an ECS cluster Read ECS FAQs
{kind=link}
{kind=link}
Page 14
Well Architected framework
The well architected framework provides - Strategies and best practices for architecting in the cloud It provides you a way to measure your architecture against AWS best practices Address shortcomings in your architecture What does the Well architected framework comprise of - Pillars - Security Reliability Operational Excellence Cost optimization Performance Efficiency Design Principles - For all the above pillars Questions - Questions you should ask to evaluate how your architecture is aligned in comparison to the AWS best practices. Well architected framework was created to - Ensure customers are thinking cloud natively Provide a consistent approach to evaluating architectures Ensure that customers are thinking about the foundational areas that are often neglected. General design principles - Stop guessing your capacity needs Test systems at production scale Automate to make architectural experimentation easier Allow for evolutionary architectures Data driven architectures Improve through game days Focus Areas for pillars Operational Excellence pillar - The ability to run and monitor systems to deliver business value and to continually improve upon supporting processes and procedures. Prepare Set operational priorities based on business needs, needs of development teams, compliance and regulatory requirements. Balance the risk of decisions against their potential benefit. Design for operations Perform operational readiness Operate Understand operational health Derive business and operational insights Respond to events Example would be the event, incident and problem management process of the organization Evolve Learn from experience Share learnings Example would be the use of feedback loops to gain feedback and use the feedback to improve operations Security Pillar - Ability to protect information, systems and assets while delivering business value through risk assessment and mitigation strategies Identity and access management AWS IAM Role based access (RBAC) Permissions Multifactor authentication Federation Data Protection Encrypt data and manage keys Detailed logging Storage resiliency Versioning Infrastructure Protection Edge Protection Monitoring ingress and egress traffic Logging Monitoring and alerting Detective Controls Lifecycle controls to establish operational baselines Use internal auditing to examine controls Automated alerting Incident Response Easy way to get access for security incident and response teams Right, pre deployed tools such as a templated clean rooms (trusted environment to conduct your investigations) Reliability - Ability of a system to recover from infrastructure or service failures, dynamically acquire resources to fulfil demand and mitigate disruptions such as misconfiguration and transient network issues Foundations Sufficient Network bandwidth/Manage your network topology Manage AWS service limits High availability Change management Be aware of how a change effects the system and plan proactively Monitor to quickly identify trends Failure management Automated actions in response to demand Analyze failed resources out of band Back up your data regularly Performance Efficiency - Ability to use computing resources efficiently to meet system requirements and to maintain that efficiency as demand changes and technologies evolve. Selection Select appropriate resource types Review Benchmark and load test Monitoring Use Cloudwatch to monitor and send notification alarms Use automation to work around performance issues by triggering actions through services such as SQS, Lambda, Cloudwatch, Kninesis Trade offs Place cached data closer to user to reduce access time Use AWS global infrastructure to achieve lower latency and higher throughput Test new approaches and capabilities Monitor performance Cost Optimization- Ability to avoid or eliminate unneeded cost or sub-optimal resources Cost effective resources Use appropriate instances and resources to optimize cost Use managed services Match demand and supply Provision resources to match demand. Demand can be - Demand based (need for more instances - Autoscaling) Queue based (frontend sending requests at a faster rate than backend can process - SQS) Schedule based (Dev/Test and DR) Use auto scaling to add/reduce instances based on demand Monitor and benchmark demand and performance Expenditure awareness Tag resources Track project resources and profile applications Monitor cost and usage cost explorer Partner tools Optimize over time Stay up to date with new services and features Decommission resources or services that are no longer in use Design Principles - Operational Excellence Perform Operations with code Annotated documentation Make frequent, small, reversible changes Refine operations procedures frequently Anticipate failure Learn from all operational failures Security Identity and access management Data Protection Infrastructure Protection Detective Controls Incident Response Reliability Foundations Change Management Failure management Performance efficiency Democratize advanced technologies Go global in minutes Use serverless architecture Experiment more Mechanical sympathy Cost Optimization Cost effective resources Match demand and supply Expenditure awareness Optimizing over time Key services - Operational Excellence - Main service - AWS Cloudformation Other services Prepare - AWS Config and Config rules Operate - Amazon Cloudwatch Evolve - Amazon Elasticsearch Security - Main Service - AWS IAM Other services - IAM - AWS IAM, Amazon Organization, MFA, Temporary security credential Data protection - AWS KMS, Amazon Macie, S3, EBS, RDS, ELB Detective controls - AWS Cloudtrail, Cloudwatch, AWS Config Infrastructure Protection - VPC, AWS Inspector, AWS Shield, AWS WAF Incident Response - IAM, Cloudformation Reliability- Main Service - Amazon Cloudwatch Other services - Foundations - IAM, VPC, TrustedAdvisor, AWS Shield Change Management - AWS Cloudtrail, Cloudwatch, AWS Config, AWS Autoscaling Failure Management - AWS Cloudformation, S3, Glacier, KMS Performance efficiency - Main service - Amazon Cloudwatch Other services - Selection - All compute, storage, database and network services Review - AWS Blogs and what's new Monitoring - AWS Cloudwatch, AWS Lambda Trade offs - Amazon Cloudfront, Amazon Elasticache, RDS, AWS Snowball Cost Optimization Main Service - Cost allocation tags Other services - Cost effective resources - Spot instances, Reserved instances, Amazon spot instances Match demand and supply - Autoscaling Expenditure awareness - Cloudwatch, Amazon SNS Optimizing over time - AWS blog and what's new, AWS Trusted advisor Other key points for each pillar - Operational Excellence Define run books and playbooks Document environments Make small changes through automation Monitor your workload, including business metrics Exercise your responses to failures Have well defined escalation management Common uses of well architected framework - Learn how to build cloud native frameworks Use as a gating mechanism before launch Build a backlog compare maturity of different teams Due diligence for acquisitions Choice of region in AWS should be based on the following requirements - Proximity to users Compliance Data residency contraints Cost For global applications, you can reduce latency to end users around the world by using the Amazon CloudFront content delivery network (CDN). Differences between traditional and cloud computing environments - IT assets as provisioned resources Global, Available, Scalable capacity Inbuilt security Architected for cost Higher level managed services Read highlighted sections of the saved whitepapers Elastic scaling can be implemented in three ways - Proactive Cyclic scaling - Periodic scaling that occurs at fixed intervals (daily, monthly, weekly, quarterly) Proactive event based scaling - Scaling when you are expecting a big surge of traffic requests due to a scheduled business event (new product launch, marketing campaigns etc.) Auto scaling based on demand - By using a monitoring service your system can send triggers to take appropriate actions so that it can scale up on down based on metrics. AWS trusted advisor checks your infrastructure in four areas - Security Cost Optimization Performance Fault tolerance Well Architected Review: Provides customer and partners a consistent approach to reviewing their workloads against current AWS best practices and gives advise on how to architect workloads for the cloud. The review is done by asking customers - a set of questions, getting their answers and categorizing these Q&As into the five pillars. It is not an audit, but a way to work together to improve the customer's architecture using best practices It is pragmatic and proven advice on architecture that is known to work Not something that you do once - it should be done throughout the lifecycle of the product or service See secure your application pic below. See shared responsibility model pic below Read highlighted part on Chapter 4 in book.
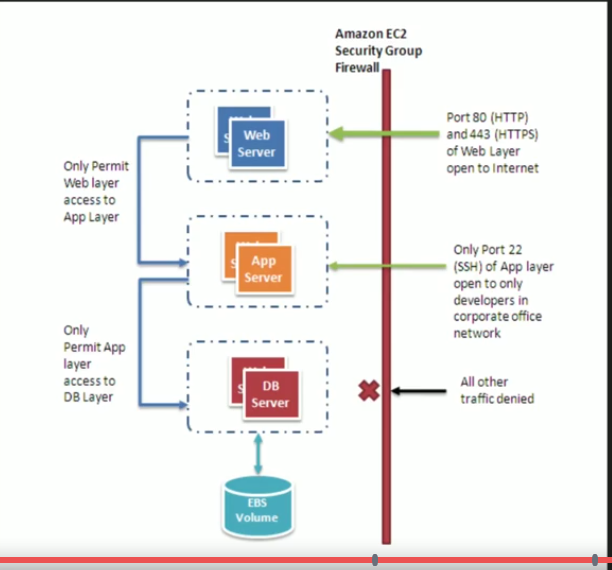{kind=link}
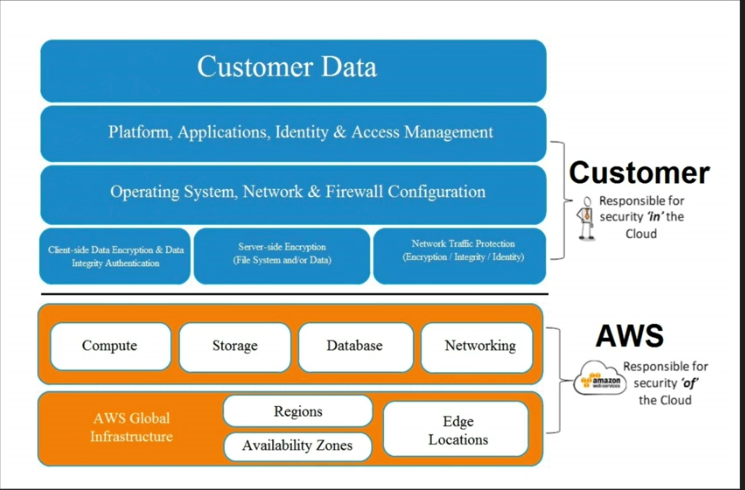{kind=link}
Page 15
Plan for last week
1. All questions at the back of chapters (AWS book) 2. Cloudguru EBS lab 3. All VPC labs 4. All notes 5. Qwiklabs 6. Auto scaling lab 7. All snipped questions from cloudguru in study folder
Till Friday 1. Revision - Services Route 53 3. Jayendra's questions Other topics - -NAT instance and NAT gateway bandwidth limits -Instance types screenshot -DynamoDB streams - Very specific question on DynamoDB table design: 000's of records inserted, analysed once then not required for analysis but still needed for archive. Prefix hashes. i.e. do you want the data partitioned or grouped together based on the scenario question. This was virtually identical to a Q on the Bonso tests. - Reboot or Stop RDS scenario. Know what happens with both, costs involved. High Availability ------------------------------------------------------ Autoscaling - Multi AZ ----Not region Read replica - multi region ELB - Multi AZ-----Not region NAT gateway - single AZ...needs to be replicated in other AZs----Not region EBS Volumes - automatically replicated across multiple AZs. EC2 and EBS have to be in same AZ ----Not region Snapshots - Can be copied to other regions EFS - Multi AZ, but same region ---- Not region VPC peering - Cross region allowed EC2 reserved instances - Restricted to region - cannot be moved outside region to another region. Can be moved between AZs ----Not region Elastic IPs - Tied to region Limits- IAM roles - 1000 per account. Limit can be increased on request Temporary token expiry - 15 minutes to 36 hours S3 object size - 0 to 5TB Min object size for S3-IA - 128 KB, Min duration - 30 days Max glacier archive size - 40 TB. Max no. of archives in a vault = 1000 Availability - Standard - 99.99, IA - 99.9, RRS - 99.5, Intelligent tiering - 99.9% Availability for EBS and EC2 - 99.99% Default Cloudfront TTL - 24 hours. Min - 0 sec for web distributions, 3600sec/1 hour for RTMP Tags limit per instance - 50 EC2 limit per region - 20. Can get more by filling form Default retention time for Cloudwatch metrics = 2 weeks. Max number of alarms that can be configured on Cloudwatch = 5000 SQS message retention can be between 1 minute and 14 days - default is 4 days Message size limit = 256KB Visibility timeout default = 30 secs, Maximum = 12 hours Long polling wait time = 20 secs max SQS queue is deleted after 30 days if not used SWF - Maximum history retention period - 1 year Long polling default time for task lists - 60 secs Kinesis Stream data retention is 24 hrs by default. Maximum is 7days/1 week API caching - Default 300 sec/5 minutes. Maximum 3600s/1hour Port numbers - https - 443 , 2049 - NFS, SQL - 3306 Cloudtrail delivers log files within 15 minutes of an API call Temporary - Ephemeral storage for Lambda function = 512MB Memory allocation for Lambda function - 128MB to 3008 MB (in 64 MB increments) Default limit for no. of launch configurations is 100/region (can be updated through command) Deafult idle timeout for ELB = 60 secs/1minute Connection draining timer after which ELB closes connection to unhealthy/deregistering instances - 1sec to 3600 sec. Default is 5 mins/300sec Default validity of STS token for SAML federation - 1 hour Back up retention period for RDS - 1 (default) to 35 days Error Codes Error 429 - Too many requests/throttling Error 504 - Load Balancer responds with this error when your application stops responding due to issue at the app or DB layer. Check what is causing and scale in/scale out instances
Page 16
Plan for morning
Notes on plan for last week Well architected framework
Want to create your own Notes for free with GoConqr? Learn more.