5360492
Description
Mind Map by Zulma Salas, updated more than 1 year ago
|
|
Created by Zulma Salas
over 8 years ago
|
|
Big Data
- Análsis de Herramientas
- Hadoop es un proyecto de Apache de código libre Hadoop
permite la creación de aplicaciones para procesar grandes
volúmenes de información distribuida a través de un modelo de
programación sencillo.
- HADOOP 1.0
- El proyecto original de Hadoop
se construyó sobre tres
bloques fundamentales: HDFS,
MapReduce,Hadoop Common
- HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
Annotations:
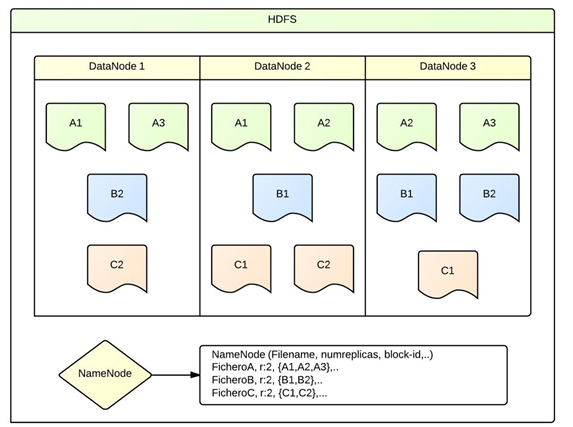
- HDFS es el sistema de ficheros distribuido sobre el que se ejecutan las aplicaciones Hadoop y que proporciona un buen número de características al sistema.
- características : Sistema de ficheros
amigable,Tolerancia a fallos de
hardware,Acceso en streaming,Grandes
cantidades de datos,Modelo simple y
coherente,Portabilidad,Escalabilidad
simple
- ARQUITECTURA HDFS
- ARQUITECTURA HDFS
- MAPREDUCE 1.0
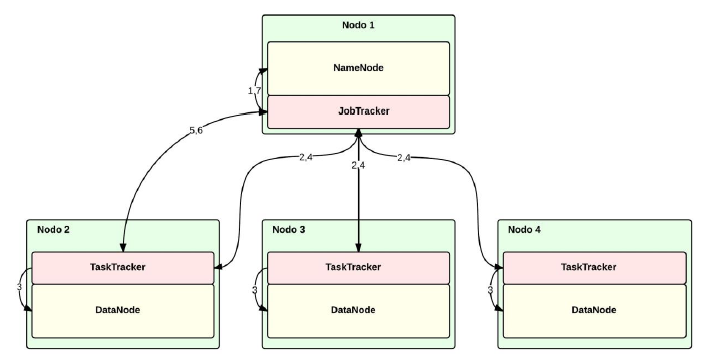
- Está basada en los documentos que Google
.MapReduce- y está preparada para trabajar con
HDFS y, por lo tanto, para que se ejecute sobre el
mismo clúster. De esta manera obtiene algunas de
las características que ofrece el sistema de ficheros
de Hadoop como la alta disponibilidad de los
datos, su distribución y la integridad del sistema.
- ARQUITECTURA MAPREDUCE
- ARQUITECTURA MAPREDUCE
- Está basada en los documentos que Google
.MapReduce- y está preparada para trabajar con
HDFS y, por lo tanto, para que se ejecute sobre el
mismo clúster. De esta manera obtiene algunas de
las características que ofrece el sistema de ficheros
de Hadoop como la alta disponibilidad de los
datos, su distribución y la integridad del sistema.
- HADOP COMMON
- Proporciona acceso a los sistemas de archivos
soportados por Hadoop. El paquete de software The
Hadoop Common contiene los archivos .jar y los
scripts necesarios para hacer correr Hadoop. El
paquete también proporciona código fuente,
documentación, y una sección de contribución que
incluye proyectos de la Comunidad Hadoop.
- Proporciona acceso a los sistemas de archivos
soportados por Hadoop. El paquete de software The
Hadoop Common contiene los archivos .jar y los
scripts necesarios para hacer correr Hadoop. El
paquete también proporciona código fuente,
documentación, y una sección de contribución que
incluye proyectos de la Comunidad Hadoop.
- HADOOP DISTRIBUTED FILE SYSTEM (HDFS)
- El proyecto original de Hadoop
se construyó sobre tres
bloques fundamentales: HDFS,
MapReduce,Hadoop Common
- HADOOP 2.0
- Está dividido esta vez en cuatro módulos:
• Hadoop Common • Hadoop Distributed
File System (HDFS) • Hadoop YARN: un
framework para la gestión de
aplicaciones distribuidas y de recursos de
sistemas distribuidos. • Hadoop
MapReduce: el sistema de procesamiento
principal, que esta vez se ejecuta sobre
YARN.
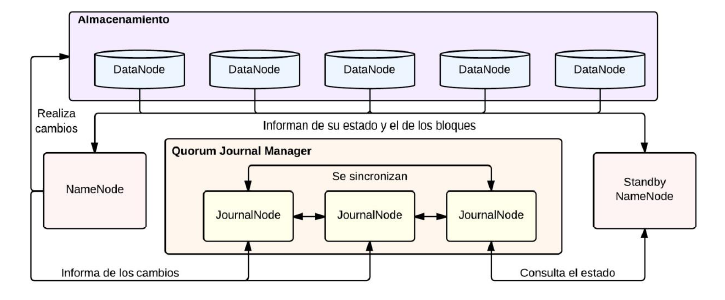
- HDFS 2.0
- Los cambios introducidos en HDFS han sido
pocos pero significativos. Se intenta
combatir la principal debilidad de la
primera versión: el NameNode como punto
de fallo único en el sistema. Esto evita que
un sistema HDFS tenga alta disponibilidad,
ya que un fallo en el NameNode hace que
el sistema deje de funcionar. Otra novedad
introducida es la HDFS Federation, que
permite tener múltiples espacios de
nombres en HDFS
- Los cambios introducidos en HDFS han sido
pocos pero significativos. Se intenta
combatir la principal debilidad de la
primera versión: el NameNode como punto
de fallo único en el sistema. Esto evita que
un sistema HDFS tenga alta disponibilidad,
ya que un fallo en el NameNode hace que
el sistema deje de funcionar. Otra novedad
introducida es la HDFS Federation, que
permite tener múltiples espacios de
nombres en HDFS
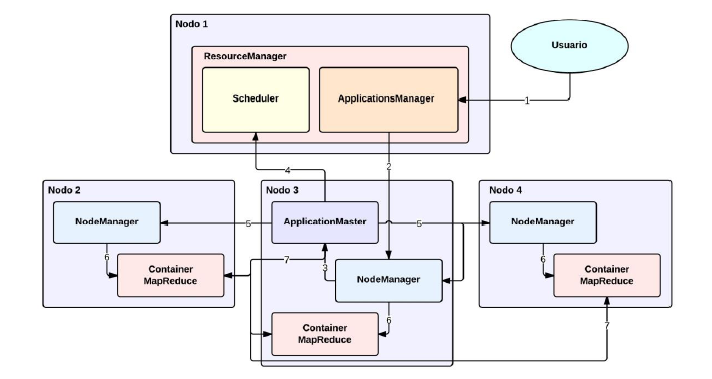
- MapReduce 2.0
- MapReduce 2.0 -o MRv2- es la capa que más cambios
ha sufrido con la segunda versión de Hadoop. Se ha
mantenido todas las características que identifican a
MapReduce a nivel de usuario: las fases de un
proceso; pero se ha renovado por completo su
arquitectura y los servicios que la componen.
- ARQUITECTURA YARN
- ARQUITECTURA YARN
- MapReduce 2.0 -o MRv2- es la capa que más cambios
ha sufrido con la segunda versión de Hadoop. Se ha
mantenido todas las características que identifican a
MapReduce a nivel de usuario: las fases de un
proceso; pero se ha renovado por completo su
arquitectura y los servicios que la componen.
- Está dividido esta vez en cuatro módulos:
• Hadoop Common • Hadoop Distributed
File System (HDFS) • Hadoop YARN: un
framework para la gestión de
aplicaciones distribuidas y de recursos de
sistemas distribuidos. • Hadoop
MapReduce: el sistema de procesamiento
principal, que esta vez se ejecuta sobre
YARN.
- HADOOP 1.0
- El proyecto Hadoop está construido básicamente sobre dos
módulos: • Hadoop Distributed File System (HDFS): el sistema de
ficheros sobre el que se ejecutan la mayoría de las herramientas
que conforman el ecosistema Hadoop. • Hadoop MapReduce: el
principal framework de programación para el desarrollo de
aplicaciones y algoritmos.
- HERRAMIENTAS HADOOP
- Utilidades
- Avro
- Avro es un sistema para la serialización de datos y
uno de los principales métodos para transportar
información entre las herramientas y aplicaciones
Hadoop.
- Avro es un sistema para la serialización de datos y
uno de los principales métodos para transportar
información entre las herramientas y aplicaciones
Hadoop.
- ZooKeeper
- Es un servicio centralizado que se encarga
de administrar y gestionar la coordinación
entre procesos en sistemas distribuidos. El
objetivo de Apache con ZooKeeper es el de
librar a los desarrolladores la tarea de
implementar funciones de mantenimiento
entre sus procesos, como la sincronización
entre estos, y ofrecer alta disponibilidad a
través de servicios redundantes.
- Es un servicio centralizado que se encarga
de administrar y gestionar la coordinación
entre procesos en sistemas distribuidos. El
objetivo de Apache con ZooKeeper es el de
librar a los desarrolladores la tarea de
implementar funciones de mantenimiento
entre sus procesos, como la sincronización
entre estos, y ofrecer alta disponibilidad a
través de servicios redundantes.
- Solr
- Es un motor de búsqueda basado en el
Apache Lucene, escrito en Java y que facilita a
los programadores el desarrollo de
aplicaciones de búsqueda. Lucene ofrece
indexación de información, tecnologías para
la búsqueda así como corrección ortográfica,
resaltado y análisis de información, entre
otras muchas características
- Es un motor de búsqueda basado en el
Apache Lucene, escrito en Java y que facilita a
los programadores el desarrollo de
aplicaciones de búsqueda. Lucene ofrece
indexación de información, tecnologías para
la búsqueda así como corrección ortográfica,
resaltado y análisis de información, entre
otras muchas características
- Avro
- Recolección de datos
- Chukwa
- Es una herramienta principalmente pensada para trabajar sobre logs y realizar análisis. Para
cumplir con este propósito Chukwa ofrece un sistema flexible para recolectar datos de
forma distribuida y para realizar su procesamiento que, a la vez, es adaptable a las nuevas
tecnologías de almacenamiento que van apareciendo
- Es una herramienta principalmente pensada para trabajar sobre logs y realizar análisis. Para
cumplir con este propósito Chukwa ofrece un sistema flexible para recolectar datos de
forma distribuida y para realizar su procesamiento que, a la vez, es adaptable a las nuevas
tecnologías de almacenamiento que van apareciendo
- Flume
- Es una herramienta distribuida para la recolección, agregación
y transmisión de grandes volúmenes de datos. Ofrece una
arquitectura basada en la transmisión de datos por streaming
altamente flexible y configurable pero a la vez simple
- Es una herramienta distribuida para la recolección, agregación
y transmisión de grandes volúmenes de datos. Ofrece una
arquitectura basada en la transmisión de datos por streaming
altamente flexible y configurable pero a la vez simple
- Chukwa
- Almacenamiento
- Cassandra
- Es una base de datos NoSQL, mayormente desarrollada por Datastax aunque empezó
como un proyecto de Facebook, escrita en Java y open-source -también es un proyecto
Apache-. Entre sus características se encuentra la de ofrecer alta disponibilidad de los
datos junto con una gran capacidad para escalar linealmente, además de ser tolerante a
fallos -no tiene un punto de fallo único- y compatible con hardware de bajo presupuesto
o infraestructuras en la nube -cloud-.
- Es una base de datos NoSQL, mayormente desarrollada por Datastax aunque empezó
como un proyecto de Facebook, escrita en Java y open-source -también es un proyecto
Apache-. Entre sus características se encuentra la de ofrecer alta disponibilidad de los
datos junto con una gran capacidad para escalar linealmente, además de ser tolerante a
fallos -no tiene un punto de fallo único- y compatible con hardware de bajo presupuesto
o infraestructuras en la nube -cloud-.
- Hive
- Es una herramienta para data warehousing que facilita la creación, consulta y
administración de grandes volúmenes de datos distribuidos en forma de tablas
relacionales. Cuenta con un lenguaje derivado de SQL, llamado Hive QL, que
permite realizar las consultar sobre los datos. Por esta misma razón, se dice que
Hive lleva las bases de datos relacionales a Hadoop. A su vez, Hive QL está
construido sobre MapReduce, de manera que se aprovecha de las características
de éste para trabajar con grandes cantidades de datos almacenados en Hadoop.
Esto también provoca que Hive no ofrezca respuestas en tiempo real.
- Es una herramienta para data warehousing que facilita la creación, consulta y
administración de grandes volúmenes de datos distribuidos en forma de tablas
relacionales. Cuenta con un lenguaje derivado de SQL, llamado Hive QL, que
permite realizar las consultar sobre los datos. Por esta misma razón, se dice que
Hive lleva las bases de datos relacionales a Hadoop. A su vez, Hive QL está
construido sobre MapReduce, de manera que se aprovecha de las características
de éste para trabajar con grandes cantidades de datos almacenados en Hadoop.
Esto también provoca que Hive no ofrezca respuestas en tiempo real.
- Cassandra
- Desarrollo de procesos para el tratamiento de datos
- Mahout
- Es una librería Java que
contiene básicamente
funciones de aprendizaje y
que está construida sobre
MapReduce.está pensada para
trabajar con grandes
volúmenes de datos y en
sistemas distribuidos -aunque
también está diseñado para
funcionar en sistemas no
Hadoop y no distribuidos
- Es una librería Java que
contiene básicamente
funciones de aprendizaje y
que está construida sobre
MapReduce.está pensada para
trabajar con grandes
volúmenes de datos y en
sistemas distribuidos -aunque
también está diseñado para
funcionar en sistemas no
Hadoop y no distribuidos
- Oozie
- Es un planificador de workflows para sistemas que
realizan trabajos o procesos Hadoop. Proporciona
una interfaz de alto nivel para el usuario no técnico
o no experto y que gracias a su abstracción permite
a estos usuarios realizar flujos de trabajo complejos
- Es un planificador de workflows para sistemas que
realizan trabajos o procesos Hadoop. Proporciona
una interfaz de alto nivel para el usuario no técnico
o no experto y que gracias a su abstracción permite
a estos usuarios realizar flujos de trabajo complejos
- Pig
- Es una herramienta para
analizar grandes
volúmenes de datos
mediante un lenguaje
de alto nivel -PigLatin-
que está diseñado para
la paralelización del
trabajo. Mediante un
compilador se traducen
las sentencias en
PigLatin a trabajos
MapReduce sin que el
usuario tenga que pasar
a programar ni tener
conocimientos sobre
ellos
- Es una herramienta para
analizar grandes
volúmenes de datos
mediante un lenguaje
de alto nivel -PigLatin-
que está diseñado para
la paralelización del
trabajo. Mediante un
compilador se traducen
las sentencias en
PigLatin a trabajos
MapReduce sin que el
usuario tenga que pasar
a programar ni tener
conocimientos sobre
ellos
- Mahout
- Administración
- Hue
- es una herramienta que proporciona a los usuarios y administradores de las distribuciones Hadoop
una interfaz web para poder trabajar y administrar las distintas herramientas instaladas. De esta
manera Hue ofrece una serie de editores gráficos, visualización de datos y navegadores para que los
usuarios menos técnicos puedan usar Hadoop sin mayores problemas. Hue es una herramienta
principalmente desarrollada por Cloudera -6.1. Cloudera-, razón por la que cuenta con algunas
características de su distribución, como un editor para Impala.
- es una herramienta que proporciona a los usuarios y administradores de las distribuciones Hadoop
una interfaz web para poder trabajar y administrar las distintas herramientas instaladas. De esta
manera Hue ofrece una serie de editores gráficos, visualización de datos y navegadores para que los
usuarios menos técnicos puedan usar Hadoop sin mayores problemas. Hue es una herramienta
principalmente desarrollada por Cloudera -6.1. Cloudera-, razón por la que cuenta con algunas
características de su distribución, como un editor para Impala.
- Hue
- Utilidades
- Hadoop es un proyecto de Apache de código libre Hadoop
permite la creación de aplicaciones para procesar grandes
volúmenes de información distribuida a través de un modelo de
programación sencillo.
Media attachments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Want to create your own Mind Maps for free with GoConqr? Learn more.